Changes: Detailed Release Notes Includes versions: JBossAS-5.0.0.GA Feature Request * [ JBAS-70 ] Security event listener that could be plugged in to listen to authentication and authorization events. * [ JBAS-3767 ] Create a canonical "JndiServiceMBeanSupport" useful for binding objects to JNDI * [ JBAS-3997 ] getManagedConnection retries * [ JBAS-4588 ] DeploymentSorter in the new profile service based deployment scanner * [ JBAS-5192 ] ServiceBindingManager that can handle pojo services * [ JBAS-5348 ] Move remoting configuration into deploy * [ JBAS-5535 ] Modularisation of the JBoss Bootstrap * [ JBAS-5545 ] Implement the jsr77 view on top of the new deployers/profileservice/mc * [ JBAS-5766 ] Add new aop deployers * [ JBAS-5900 ] jars are not loaded from the lib directory of a sar in JBoss AS 5 * [ JBAS-5960 ] EJB2: Lack of security domain in JBoss DD does not bypass security * [ JBAS-5966 ] Migrate TomcatService mbean deployment descriptor to mc bean descriptor * [ JBAS-5974 ] Turn of deployment of base-aspects.xml by default * [ JBAS-5975 ] Switch to MC based AOP deployers * [ JBAS-5989 ] Security Beans need ManagedObject annotations * [ JBAS-5998 ] Add resources filtering to MetaDataAwareProfile * [ JBAS-6013 ] Support createDestination in jboss/message-driven * [ JBAS-6032 ] Refactor AOPClassLoaderDeployer * [ JBAS-6058 ] Web descriptors parsing * [ JBAS-6070 ] Need an overview of the profile service in the 5.0 docs * [ JBAS-6088 ] Add simple cache / cluster support for Spring beans * [ JBAS-6099 ] add alternate, not meta data based JSF injection provider * [ JBAS-6130 ] AS5:JACC: * in web.xml should allow configurable authorization bypass * [ JBAS-6136 ] Pojoize the jca configuration * [ JBAS-6158 ] Reduce the distribution size by sharing the libraries between the all and default configs * [ JBAS-6182 ] Add support for JBC MVCC locking in Hibernate 2nd Level Cache configs * [ JBAS-6205 ] Make server.log logging level configurable via system property * [ JBAS-6223 ] Externalize the DeploymentRepository attachments location * [ JBAS-6267 ] Introduce SecurityContextInterceptor in the ejb2 proxy Bug * [ JBAS-2149 ] ByValueContainerInvoker * [ JBAS-5081 ] New transaction manager does not implement TransactionTimeoutConfiguration properly * [ JBAS-5114 ] MessageDriven EJB3 does not create destination automatically * [ JBAS-5115 ] Valid jboss-app.xml file not recognized correctly by jbossxb runtime * [ JBAS-5209 ] Hot deployment scanner deploys files which were expected to be filtered * [ JBAS-5301 ] JaasSecurityManagerService.startService - java.lang.IllegalArgumentException: handler exists * [ JBAS-5412 ] BaseLocalProxyFactory should not check for explicit security context * [ JBAS-5689 ] Not seeing bootstrap ManagedDeployment/ManagedComponents * [ JBAS-5732 ] Deployment of @WebService fails * [ JBAS-5767 ] Security schemas * [ JBAS-5895 ] OptAnnotationMetaDataDeployer is processing too many classes * [ JBAS-5942 ] Session replication with passivation causes inconsistent session data * [ JBAS-5943 ] JRMPInvokerProxyHA should not failover if PooledInvokerProxy.invoke() throws java.rmi.ConnectException with cause of java.io.EOFException * [ JBAS-5951 ] ProfileService unit tests are not validating persistence of updates * [ JBAS-5964 ] NPE in expiration of passivated sessions * [ JBAS-5968 ] NullPointerException in WebServiceDeployerEJB * [ JBAS-5978 ] Mask password logging in ServiceConfigurator * [ JBAS-5979 ] java.lang.NoClassDefFoundError: org/jboss/aop/pointcut/ast/PointcutExpressionParserVisitor in EJB client * [ JBAS-5999 ] EJBTimerServiceImpl timerServiceMap access should be synchronized * [ JBAS-6002 ] NPE for JSF managed beans. * [ JBAS-6007 ] Wrong bean name when EJB is not deployed within an ear * [ JBAS-6017 ] JRMPProxyFactory should rebind the proxy in JNDI rather than just bind it * [ JBAS-6028 ] Bootstrap dependencies failure of ejb3 session beans * [ JBAS-6040 ] Ensure correct TCCL is set before accessing clustered web session cache * [ JBAS-6041 ] let the web metadata override a default context-param * [ JBAS-6044 ] JMX console invokeOp confused ObjectName encoding * [ JBAS-6056 ] UserTransaction cannot be deployed as clustered proxy and sticky transactions randomly work * [ JBAS-6060 ] Tolerate security domain convention in JBoss DD * [ JBAS-6062 ] Exploded WAR archive with no web.xml is no longer supported * [ JBAS-6067 ] XACML policy is not removed when deployment unit is undeployed * [ JBAS-6068 ] Mask passwords in the Deployers * [ JBAS-6077 ] seam-int: hot-redeploys occur constantly on JBoss 5 trunk * [ JBAS-6076 ] Seam war not using jboss-seam-int * [ JBAS-6093 ] Exposing the EMF in JNDI via jboss.entity.manager.factory.jndi.name doesn't work in JBoss 5.0.0.CR2 * [ JBAS-6098 ] juddi-service.sar bundles juddi.jar & scout.jar * [ JBAS-6107 ] Seam hibernate and jpa examples throw ZipExceptions during deployment - but the jars are valid * [ JBAS-6110 ] Tomcat status in the web-console missing logo * [ JBAS-6111 ] Ensure hibernate.cache.region_prefix is specified by PersistenceUnitDeployment * [ JBAS-6116 ] UserTransaction.commit()/rollback() are not fully compliant with the JTA standard * [ JBAS-6117 ] IOException in VFS while undeploying a Seam example * [ JBAS-6131 ] EJB1.1 isCallerInRole must throw RTE if role is not found in deployment descriptor * [ JBAS-6135 ] Concurrent connection of HAPartition channels fails * [ JBAS-6147 ] Profile.getModifiedDeployments() does not ignore .bak file * [ JBAS-6149 ] connectionMap.remove in WrapperDatasourceService never called * [ JBAS-6153 ] Transaction sticky target not available should be thrown as ServiceUnavailableException * [ JBAS-6161 ] Two ears with a same named jar fails to deploy * [ JBAS-6162 ] Error logged when attempting to passivate invalidated session * [ JBAS-6165 ] NPE in TransactionScopedEntityManager * [ JBAS-6174 ] shutdown.jar is missing classes * [ JBAS-6176 ] appclient doesn't declare a dependency on persistence unit * [ JBAS-6177 ] Error on jchannel.getState() right after connect (even with flush) * [ JBAS-6181 ] cannot secure jmx invoker service * [ JBAS-6193 ] JBossCacheManager leaks ReplicationStatistics.TimeStatistic * [ JBAS-6194 ] Move transaction sticky logic in proxy to interceptors to avoid bottleneck * [ JBAS-6206 ] JBossManager sets invalid session cookie after failover * [ JBAS-6207 ] update jts install for new lib layout * [ JBAS-6209 ] DelegatingClassloader is trying to get the parent in an unprivileged block * [ JBAS-6214 ] Default port bindings overriding (bindings.xml) doesn't work. * [ JBAS-6224 ] SecurityContextEstablishmentValve is making expensive loadClass calls * [ JBAS-6229 ] Resolving of relative persistence units doesn't work * [ JBAS-6231 ] jboss.messaging.jar (server) on /client * [ JBAS-6239 ] Regression on run-as in a MDB * [ JBAS-6241 ] EJB TIMERS Table Creation Fails When Oracle Schema Specified * [ JBAS-6243 ] EJB2: Reintroduce explicit run as check before authentication * [ JBAS-6252 ] Messaging release is missing connection-factories-service.xml * [ JBAS-6256 ] NPE during undeployment of test artifact /bundled-myfaces-hellojsf.war * [ JBAS-6275 ] Fix *both* 4.2.x & 5.0.x compatibility matrix tests Task * [ JBAS-2563 ] Cleanup the build for jboss5 * [ JBAS-3916 ] Update source code headers. * [ JBAS-4370 ] SecurityDeployer: XACML/acl Policy Registration * [ JBAS-4814 ] Refactor the conf/jboss-service.xml services * [ JBAS-4967 ] Extract setting of default clustering JBossWebMetaData from TomcatDeployer * [ JBAS-5078 ] Validate SRP Configuration * [ JBAS-5234 ] Include the Windows Service Runner binary (jbossvc.exe) in the distro * [ JBAS-5358 ] Move remote access to profile service into deploy * [ JBAS-5677 ] Add discussion of usage of FC to Clustering Guide * [ JBAS-5778 ] Improve HttpSessionListener handling in clustered environment * [ JBAS-5794 ] Administration and configuration guide * [ JBAS-5795 ] Administration and configuration guide * [ JBAS-5872 ] Update org.jboss.test.compatibility.test.SerialVersionUIDUnitTestCase * [ JBAS-5873 ] Create JBoss-AS-5.0.x-CompatibilityMatrix test run based on the 4.2.x one * [ JBAS-5883 ] Unify name usage in ProfileService * [ JBAS-5908 ] ClientUserTransactionObjectFactory is inefficient * [ JBAS-5930 ] Investigate ENC issues to obtain JBoss Security Manager in the web layer * [ JBAS-5945 ] Make JBossCacheClusteredSession.initAfterLoad() part of an override of update() * [ JBAS-5958 ] Fix any remaining testsuite failures * [ JBAS-5963 ] ClientUserTransaction should log cause exceptions * [ JBAS-5977 ] FIXME the HackClassloaderMetaDataDeployer boot WARN * [ JBAS-5988 ] AS5 Codebase Privileged Blocks * [ JBAS-5994 ] Switch to repository based ProfileService as the default * [ JBAS-6023 ] Inject Naming instance into DetachedHANamingService * [ JBAS-6030 ] Uncomment @JMX annotation in deployers.xml to enable JMX management of DeployersImpl * [ JBAS-6039 ] Change JGroups thread pool rejection policy to 'Discard' * [ JBAS-6064 ] JSR-196 integration for web layer * [ JBAS-6080 ] On Linux, HA-JNDI to pass SocketAddress to MulticastSocket constructor * [ JBAS-6081 ] Remove TUNNEL config * [ JBAS-6084 ] Reduce Logging Visibility when setting DefaultJndiBindingPolicy (when not explicitly specified) * [ JBAS-6087 ] Reduce the excessive logging * [ JBAS-6090 ] Convert legacy clustered services to pojo configuration * [ JBAS-6091 ] Allow JRMPInvoker to work as an MC bean * [ JBAS-6103 ] Review the 'minimal' config * [ JBAS-6105 ] Improve start-up time * [ JBAS-6109 ] ClusteredSession should not subclass StandardSession * [ JBAS-6129 ] Missing licenses * [ JBAS-6132 ] Revert to AS 4 behavior of handling distributable webapps in default config * [ JBAS-6143 ] Remove legacy persistence unit resolving functions from appclient and tomcat * [ JBAS-6148 ] Port metadata awareness to the repository profileservice * [ JBAS-6154 ] Verify JAXB version for 5.0.0.GA release * [ JBAS-6159 ] Make an integration abstraction for the UserTransactionListener and CachedConnectionManager * [ JBAS-6160 ] Component Update to jboss-ejb3-as-int * [ JBAS-6163 ] JACC: Look at the cmp2-audit.jar for security domain * [ JBAS-6169 ] Make "bootstrap" module reusable * [ JBAS-6170 ] Update package names moved from "main" to "bootstrap" * [ JBAS-6172 ] org.jboss.system.server.Server should be JVM-agnostic * [ JBAS-6183 ] ATTRIBUTE granularity clustered session should store attribute in same JBC node as metadata * [ JBAS-6184 ] Eliminate a JBC Fqn level in clustered session caching * [ JBAS-6186 ] Use JBossWebMetaData to drive DistributedCacheManagerFactory * [ JBAS-6189 ] Add plain reports to the test target * [ JBAS-6201 ] Eliminate injection of DistributedReplicantManagerImpl into ClusterPartition * [ JBAS-6237 ] Remove the old JMX kernel's dependency on the Deployment layer * [ JBAS-6238 ] Remove JBossMQ from the 5.0.0 branch * [ JBAS-6249 ] Pick a different port for the JBM Data channel's MPING * [ JBAS-6254 ] Provide an implementation for ejb3 CachedConnectionManager SPI * [ JBAS-6261 ] Rename cluster-jboss-beans.xml to hapartition-jboss-beans.xml * [ JBAS-6263 ] Use Microcontainer to build JBC configs * [ JBAS-6271 ] Create a 'standard' config out of the 'cts' one. * [ JBAS-6273 ] Create release notes for AS 5.0.0.GA * [ JBAS-6279 ] Remove assumption about who master is from HA Singleton test cases * [ JBAS-6280 ] Refresh the communit docs Sub-task * [ JBAS-3858 ] Update jbossweb-cluster.aop to match the current configuration * [ JBAS-5349 ] Test bootstrap dependencies * [ JBAS-5370 ] Deploy an ear/war app through ProfileService * [ JBAS-5856 ] SBM-compatible JBM remoting connector config * [ JBAS-5858 ] Add @JMX annotation to ServiceBindingManager * [ JBAS-5953 ] JBoss-AS-5.0.x-TestSuite-sun16-sun16 - org.jboss.test.jmx.test.UndeployBrokenPackageUnitTestCase * [ JBAS-5969 ] Remove dependency of AOP on VFSDeploymentUnit * [ JBAS-5970 ] Remove dependency of AOP on ServiceMBeanSupport * [ JBAS-5984 ] Make names unique in jbossweb-cluster.aop/META-INF/jboss-aop.xml * [ JBAS-5985 ] Make the switch in aop.xml and deployers.xml * [ JBAS-5986 ] Remove jboss-aop.xml from the deployment for aop.AnnotatedTestCase and aop.ScopedAnnotatedTestCase * [ JBAS-5987 ] Add new tests for scoped aspects with dependencies * [ JBAS-5996 ] Move TomcatDeployer.securityManagerService injection out of the deployer * [ JBAS-5997 ] iiop-service.xml is missing naming service dependencies * [ JBAS-6036 ] Add tests for restart of server to validate profileservice overrides are applied * [ JBAS-6037 ] Restore ProfileService attachments persistence * [ JBAS-6042 ] Remove the user of LoaderRepositoryConfig as an attachment * [ JBAS-6055 ] Use the enforcer plugin to avoid bringing in duplicate/wrong dependencies * [ JBAS-6082 ] JUDDIService.setBindJaxr cannot attempt to bind into jndi * [ JBAS-6083 ] HAPartitionCacheHandler.cache injection is broken * [ JBAS-6096 ] Upgrade ha-server-cache-jbc * [ JBAS-6121 ] Upgrate JAXR to 1.2.1.GA * [ JBAS-6124 ] regression - org.jboss.test.jcaprops.test.* * [ JBAS-6125 ] regression - org.jboss.test.deployers.seam.test.SeamVFSClassloadingUnitTestCase * [ JBAS-6139 ] Create a hudson job that builds using a clean local maven repo. * [ JBAS-6141 ] Upgrade to jboss-server-manager 1.0.0.GA and jboss-test 1.1.3.GA * [ JBAS-6146 ] JBoss-AS-5.0.x-TestSuite-jrockit16-jrockit16 - server all fails to shutdown * [ JBAS-6151 ] Upgrade JBossXACML dependency to 2.0.2.SP1 * [ JBAS-6166 ] regression - org.jboss.test.security.test.authorization.XACMLEJBIntegrationUnitTestCase * [ JBAS-6167 ] Restore the ServerInfo bean/mbean * [ JBAS-6168 ] Modify the Bootstrap spi to pass the kernel deployments loaded by the Server bootstrap * [ JBAS-6178 ] JBoss-AS-5.0.x-CompatibilityMatrix Failures * [ JBAS-6187 ] Break out profileservice spi from jboss-system.jar * [ JBAS-6190 ] repository based ProfileService hot deployment is not working * [ JBAS-6191 ] VFS URL Handler Stubs for JDK PolicyFile implementation to read vfs entries * [ JBAS-6198 ] Javadoc for ManagedOperation.invoke() says it will return a MetaValue, but it's returning unwrapped Objects * [ JBAS-6199 ] break out profileservice spis as a separate project * [ JBAS-6203 ] "config-property" property on Local Datasource managed component returns incorrect MetaType * [ JBAS-6210 ] common core to 2.2.10.GA * [ JBAS-6211 ] jboss integration to 5.0.2.GA * [ JBAS-6215 ] when creating a new Datasource via managementView.applyTemplate(), if the "metadata" CompositeValue property contains no items or a null-valued item, the ds.xml file is written with an empty "metadata" element, which causes the deployer to complain * [ JBAS-6216 ] ManagementView.getComponentsForType(type) returns null, rather than an empty Set, if no Components of the specified type are deployed * [ JBAS-6217 ] JBossWebRealm->enableAuditFlag should be false by default * [ JBAS-6234 ] ManagedProperty contains certain metadata that is not contained in MetaType * [ JBAS-6245 ] org.jboss.test.asynch.AsynchTestCase * [ JBAS-6246 ] org.jboss.test.web.test.JSFIntegrationUnitTestCase * [ JBAS-6247 ] org.jboss.test.xml.DDValidatorUnitTestCase * [ JBAS-6248 ] org.jboss.test.profileservice.override.test.JmsDestinationOverrideTestCase * [ JBAS-6251 ] 15 failures in JBossWS-3.0.4.GA-testsuite-AS5.0.x * [ JBAS-6253 ] Management interface for HAPartition and DRM * [ JBAS-6255 ] 8 test-aop-scoped failures * [ JBAS-6269 ] regression - org.jboss.test.refs.test.ResourceResolutionUnitTestCase.testClientORBResources * [ JBAS-6270 ] ManagementView.getDeploymentNames does not show the bootstrap deployment names Thirdparty Change * [ JBAS-5597 ] Track jboss and thirdparty dependencies upgrades for JBoss 5.0.0.GA Component Upgrade * [ JBAS-5382 ] Upgrade PojoCache to 3.0.0.GA * [ JBAS-5894 ] Upgrade jboss AOP to 2.0.0.GA * [ JBAS-5919 ] Upgrade jboss transactions to 4.4.0.GA * [ JBAS-5927 ] Upgrade jboss-integration spis to 5.0.1.GA * [ JBAS-6004 ] Upgrade jbossws to 3.0.4.GA * [ JBAS-6015 ] Upgrade seam-integration to 5.0.0.GA * [ JBAS-6016 ] Upgrade JBossWeb to 2.1.1.GA * [ JBAS-6018 ] Upgrade jboss-javaee apis to 5.0.0.GA * [ JBAS-6019 ] Upgrade JBoss Aspects to their final version * [ JBAS-6021 ] Upgrade jboss-security to 2.0.2.SP3 * [ JBAS-6022 ] Upgrade jboss vfs to 2.0.0.GA * [ JBAS-6024 ] Upgrade jbossxb to 2.0.0.GA * [ JBAS-6025 ] Upgrade to jnp-client/server 5.0.0.GA * [ JBAS-6026 ] Upgrade jboss-messaging to 1.4.1.GA * [ JBAS-6045 ] Upgrade jboss-microcontainer to 2.0.0.GA * [ JBAS-6046 ] Upgrade jboss-managed/metatype to 2.0.0.GA * [ JBAS-6048 ] Upgrade jboss-deployers to 2.0.0.GA * [ JBAS-6049 ] Upgrade jboss-reflect to 2.0.0.GA * [ JBAS-6050 ] Upgrade jboss-mdr to 2.0.0.GA * [ JBAS-6051 ] Upgrade jboss-classloading to 2.0.1.GA * [ JBAS-6053 ] Upgrade jboss-jaxbintros to a final release * [ JBAS-6063 ] Upgrade javassist to 3.9.0.GA * [ JBAS-6065 ] Upgrade jgroups * [ JBAS-6079 ] Upgrade JBoss Cache to 3.0.1.GA * [ JBAS-6100 ] JBoss Remoting update needed * [ JBAS-6233 ] Upgrade jboss-reflect to 2.0.1.GA
'분류 전체보기'에 해당되는 글 94건
- 2009.03.16 JBoss 5.0.0 변경 내역 1
- 2009.03.13 Dual-Master Replication in MySQL 1
- 2009.03.13 오라클 관리 명령어 요약-
- 2009.03.10 JBoss 설정하기 1
- 2009.03.06 jboss 에서 datasource 설정 하기 및 테스트
- 2009.03.02 Windows에서 MySQL 설치하기
- 2009.03.02 MySQL Cluster
- 2009.03.02 MySQL리플리케이션 2
- 2009.02.25 [번역]MySQL Table Joins
- 2009.02.25 MySQL - Explain 정보보는법
송은영 (f405@sds.co.kr), 김홍섭(hskim@sds.co.kr), 방창현(winchild@sds.co.kr)-등록및포매팅 / (주)삼정데이터서비스 연구소
최종수정일: 2006년1월2일 01시35분
[edit]
1.2.2 MASTER 계정생성 ¶
slave 서버에서 master 서버에 접속할 수 있도록, master 서버에 계정을 만든다. 사용자를 추가해 주어야 한다는 말이다. 이 계정에 REPLICATION SLAVE 권한을 주어야 한다. replication에만 사용할 계정이라면 추가적인 권한은 주지 않아도 된다. slave 서버에서master 서버에 접속할 계정과 패스워드에 권한을 부여하는 명령은 다음과 같다.
master mysql > GRANT REPLICATION SLAVE ON *.* -> TO 'user_name'@'user_host' IDENTIFIED BY 'user_password';
여기서 user_name은 중복되지 않는 이름이면 되며, user_host 는 slave로 만들 서버의 주소 혹은 도메인 네임을 적어준다. 이 주소의 slave 유저만 master 서버로 접속할 수 있다. 4.0.2 이전 버전의 MySQL에서는, REPLICATION SLAVE 권한이 없으므로, 다음과 같이 FILE 권한으로 대신한다.
master mysql > GRANT FILE ON *.* -> TO 'user_name'@'user_host' IDENTIFIED BY 'user_password';
[edit]
1.2.3 MASTER 데이터 SLAVE 에 복사 ¶
master 서버의 기본 데이터를 백업 받아, slave 서버의 데이터베이스에 복사한 후, 데이터 디렉토리에서 압축을 푼다.
HOT 백업
master mysql > FLUSH TABLES WITH READ LOCK; master shell > tar -cvf /tmp/mysql-snapshot.tar . slave shell > tar -xvf /tmp/mysql-snapshot.tar master mysql > UNLOCK TABLES;
mysqldump 이용 백업
master Shell > mysqldump -u root -p ‘password’ -B db_name > dump_file.sql
[edit]
1.2.4 MASTER 환경설정 ¶
Master 와 Slave 의 데이터 베이스 환경을 설정한다. 우선 master 서버를 설정하도록 한다.
master shell> vi /etc/my.cnf
master 서버는 디폴트로 구성이 되어 있을 것이므로, mysqld 섹션에 log-bin이 있는 지 확인한다.
[mysqld]
log-bin
server-id = 1
[edit]
1.2.5 SLAVE 환경설정 ¶
다음은 slave 서버의 환경설정이다.
slave shell> vi /etc/my.cnf
mysqld 섹션으로 가서 server-id를 master 서버의 server-id와 다르게 설정한다. 본 문서에서는 2로 설정하도록 하겠다. slave 서버를 여러 대로 구축하고자 할 때에 각 slave 서버의 server-id는 각각 달라야 한다는 것에 주의하자. 2^32-1까지 가능하다.
[mysqld] server-id = 2 master-host = xxx.xxx.xxx.xxx(user_host) master-port = 3306 master-user = user_name master-password = user_password
master 서버의 데이터를 백업 받았다면, slave 서버를 시작하기 전에 slave 서버의 데이터 디렉토리에 master 서버의 데이터를 복사해 둔다. mysqldump를 사용했다면, 다음으로 가서 먼저, slave 서버를 스타트한다.
[edit]
1.2.7 SLAVE 덤프파일 LOAD ¶
mysqldump를 사용해 백업 파일을 만들었다면, slave 서버에 덤프 파일을 로드시킨다.
slave shell > mysql -u root -p < dump_file.sql
[edit]
1.2.8 MASTER 계정 설정 ¶
slave 서버에서 master-host, master-user, master-password 등의 설정을 다음과 같이 바꿀 수도 있다. 물론 /etc/my.cnf에서 설정하지 않았을 경우에도 쓸 수 있다.
slave mysql > CHANGE MASTER TO -> MASTER_HOST='master_host_name', -> MASTER_USER='replication_user_name', -> MASTER_PASSWORD='replication_password', -> MASTER_LOG_FILE='recorded_log_file_name', -> MASTER_LOG_POS=recorded_log_position;
각 옵션의 최대 길이는 다음과 같다.
MASTER_HOST 60 MASTER_USER 16 MASTER_PASSWORD 32 MASTER_LOG_FILE 255
[edit]
1.2.10 SUCCESS CERTIFICATION ¶
mysql/data/slave.err을 확인하여 다음과 같은 메시지가 있으면 성공적으로 설정된 것이다.
Slave I/O thread: connected to master 'user_name@user_host:3306', replication started in log 'FIRST' at position 4
[edit]
1.3 How to Set Up Dual-Master Replication ¶
우선 이후에서는 지금까지 master 라고 칭했던 서버를 mysql1 서버라고 하고, slave라 칭했던 서버를 mysql2 서버라 하겠다. 듀얼 마스터 리플리케이션을 구축할 두 대의 서버에는 동일 버전의 최신 MySQL이 설치되어 있으며, Master-Slave 리플리케이션이 구축된 상태에 있다고 간주한다.
이미 앞에서 리플리케이션 구축에 대해 자세히 설명하였으므로, 과정에 대해서만 기술하기로 하겠다.
[edit]
1.3.1 SLAVE STOP ¶
mysql2 서버로 이동한 후, mysql2 서버의 mysql 구동을 멈춘다.
mysql2 shell > /etc/init.d/mysqld stop
[edit]
1.3.4 GRANT REPLICATION SLAVE ¶
d. mysql2 서버에서 GRANT REPLICATION SLAVE명령을 실행한다. Dual-Master란 것이 서로가 서로의 master이자 slave가 되는 것이므로, 이전의 설치에서 slave였던 mysql2가 mysql1 서버의 유저를 slave 유저로 갖게 된다.
mysql2 mysql > GRANT REPLICATION SLAVE ON *.* -> TO 'users_name'@'users_host' IDENTIFIED BY 'users_password';
[edit]
1.3.5 MASTER SETUP ¶
이제 mysql1 서버로 이동하여, 설정을 계속한다. 우선, mysql1 서버의 mysql 구동을 멈춘다.
mysql1 shell > /etc/init.d/mysqld stop
[edit]
1.3.6 MASTER CONFIGURATION ¶
mysql1 서버의 /etc/my.cnf 파일을 수정한다. mysqld 섹션으로 가서 mysql2 서버를 마스터로 간주하도록 정보를 추가한다.
[mysqld] server-id = 1 <= 그대로 두고, 아래 내용을 추가한다. master-host = users_host master-port = 3306 master-user = users_name master-password = users_password
[edit]
1.3.8 SUCCESS CERTIFICATION ¶
mysql/data/mysql1.err을 확인하여 다음과 같은 메시지가 있으면 성공적으로 설정된 것이다.
Slave I/O thread: connected to master 'ccotti@222.112.137.172:3306', replication started in log 'FIRST' at position 4
지금까지 별다른 문제없이 설치를 진행하였다면, 각 서버의 mysql 모니터에서 데이터를 입력하고, 두 서버가 서로 연동이 되는 것을 확인할 수 있을 것이다.
[edit]
1.4 장애복구 ¶
위의 설정에서 두 대의 서버 중 한 대가 장애를 일으키는 경우 한 서버를 리부팅한다고 가정할 때, 별도의 설정이 없다면 기존의 MySQL 리플리케이션 구성에서는 두 서버 간의 동기화가 원활히 일어나지 않았다. 그런 경우 다음을 순서대로 진행하며, 장애를 복구할 수 있다. 우선 mysql1 서버를 재시작해야 한다고 가정하자.
1. mysql1의 mysql/data/ 의 mysql1-bin.*를 지운다.
2. mysql1의 mysqld를 시작한다.
mysql1 shell > /etc/init.d/mysqld start
3. mysql2의 mysql 모니터에서 다음 명령어를 실행한다.
mysql2 mysql > slave stop; mysql2 mysql > slave reset; mysql2 mysql > slave start;
[edit]
1.5 참고 ¶
● master와 slave 데이터 일치 방법
- master mysql을 정지시키고 대상 파일들을 백업(복사) - master mysql을 구동
● slave에서 'LOAD TABLE FROM MASTER' 나 'LOAD DATA FROM MASTER' 명령을
-> 이 후 변경사항들이 bin-log에 기록됨
- slave에 백업한 DB 파일들을 복사 후 구동
-> master의 bin-log를 참고하여 데이터 일치됨 ※ 이 때, 복사한 파일의 소유자(mysql인지?) 확인 철저 ※ my.cnf 설정에서 특정 DB를 선택한 경우 master와 slave 모두 동일하게 설정해야 함
(한 쪽은 설정하지 않고 한 쪽은 설정한 경우 오동작)
※ my.cnf 주의사항 : mysql_safe 실행 시 DB_DIR 옵션에 따라 불러오는 위치 달라짐 사용하기 위해서는 replication 계정에 다음은 권한 추가 필요
- SUPER, RELOAD, SELECT 권한을 replication 계정에 부여 ● 다음 명령을 통해 mysql의 내부cache를 clear시키고 쓰기 방지 가능
※ mysql 기본 테이블인 MyISAM 테이블을 사용할 경우 -
● 쓰기 방지 해제 명령
- mysql> UNLOCK TABLES;
● slave의 mysql을 replication 미적용하고 구동 방법
- /usr/local/bin/mysqld_safe --skip-slave-start ● slave 동작 구동 방법 - mysql> start slave;
● replication 정상동작 확인 ※ slave 설정 미인식 등의 문제 발생 시
mysql> change master to 명령을 사용하여 설정
- mysql> show processlist;
또는 mysql> show processlist\G ; 상세한 내용 확인
- mysql> show slave status;
또는 mysql> show slave status\G ; 상세한 내용 확인 또는 mysql> show master status;
- error 로그 확인
-오라클 9i / 10g용 관리 명령어(sql) 요약-
순전히 이기적인 용도로 사용하기 위해 대충 만든 요약본입니다.
필요하신 분은 유용하게 사용하세요.
혹시나 옮겨가실 분은 댓글이라도 달아주세요. ^^
작성자 : mirsya
http://mirsya.tistory.com
최종수정 2007년 2월 18일 일요일
※틀린 부분이나 수정이 필요 한 부분은 가차없이 알려주세요.
순전히 이기적인 용도로 사용하기 위해 대충 만든 요약본입니다.
필요하신 분은 유용하게 사용하세요.
혹시나 옮겨가실 분은 댓글이라도 달아주세요. ^^
작성자 : mirsya
http://mirsya.tistory.com
최종수정 2007년 2월 18일 일요일
※틀린 부분이나 수정이 필요 한 부분은 가차없이 알려주세요.
- !! 오렌지색 부분은 환경에 맞게 수정하세요.
- Oracle 9i / 10g 관리자 명령어 요약
- Startup / Shutdown
- Session
- Parameter File
- Control File
- Redo Log
- Tablespace
- Temporary Tablespace
- Undo Tablespace
- Database Buffer Cache
- Row Migration / Chaining
- Partitioned Table
- Deferred Constraints
- User
- Profile
- Privileges
- Role
- Export
- Import
- Direct Load
- Oracle Net - Host Naming
- Oracle Net - Local Naming
- Create DB - 9i
- Create DB - 10g
- Archive Log
- STARTUP / SHUTDOWN
- STARTUP
- startup [ nomount | mount | open [ read only ]]
- SHUTDOWN
- shutdown [ immediate | transactional | normal | abort ]
- 상태 변경
- alter database [ mount | open [ read only ]];
- STARTUP 상태 조회
- select status from v$instance;
- OPEN 상태 조회
- select open_mode from v$database;
- >>Index<<
- SESSION
- 제한 상태로 변경
- alter system enable restricted session;
- 제한 상태 조회
- select logins from v$instance;
- 사용자 SESSION 조회
- select sid, serial#, username, status from v$session;
- 사용자 SESSION 강제종료
- alter system kill session 'SID,SERIAL#';
- RESTRICTED SESSION 권한 조회
- select * from dba_sys_privs where privilege like '%RESTRICT%';
- >>Index<<
- PARAMETER FILE
- 파일구분
- spfile : binaryfile, open 상태에서 수정
- pfile : textfile, shutdown 상태에서 수정
- 파일생성
- shutdown 상태에서 수행
- create spfile from pfile;
- create pfile from spfile;
- SPFILE
- alter system set parameter_name = 'value' [ comment 'text' ]
[ scope = memory | spfile | both ] [ sid = 'sid' | '*' ]; - PFILE
- shutdown 상태에서 편집기로 편집
- >>Index<<
- CONTROL FILE
- SPFILE 사용시
- open 상태에서 명령수행
alter system set control_files = '경로1', '경로2' scope = spfile;
콘트롤 파일 복사 후 DB 재기동 - PFILE 사용시
- shutdown 상태에서 pfile 파라미터 수정
콘트롤 파일 복사 후 DB 기동 - >>Index<<
- REDO LOG
- LOGSWITCH
- 현재 사용하는 로그파일을 변경
- alter system switch logfile;
- CHECKPOINT
- active 상태의 로그파일을 inactive로 변경
- alter system checkpoint;
- LOG FILE 상태 조회
- select a.group#, a.member, b.bytes, b.status
from v$logfile a, v$log b
where a.group# = b.group#; - GROUP 추가
- alter database add logfile group 그룹번호 '파일경로' size 크기;
- alter database add logfile group 그룹번호 ('파일경로1', '파일경로2') size 크기;
- MEMBER 추가
- alter database add logfile member '파일경로' to group 그룹번호;
- GROUP / MEMBER 삭제
- alter database drop logfile group 그룹번호;
- alter database drop logfile member '파일경로';
- ※삭제 명령시 파일은 삭제되지 않음
- >>Index<<
- TABLESPACE
- TABLESPACE 조회
- select tablespace_name, status, contents, extent_management, segment_space_management
from dba_tablespaces; - DATAFILE 조회
- select tablespace_name, bytes, file_name from dba_data_files;
- TEMPFILE 조회
- select tablespace_name, bytes, file_name from dba_temp_files;
- 일반 TABLESPACE 생성
- create tablespace 테이블스페이스명 datafile '파일경로' size 크기
[ blocksize 크기] // 해당 블럭 사이즈의 db_nk_cache_size 설정 필요
[ extent management local ] // 8i 이전 필수 옵션
[ segment space management auto ] // 9i 이후 필수 옵션; - UNDO TABLESPACE 생성
- create undo tablespace 테이블스페이스명 datafile '파일경로' size 크기;
- TEMPORARY TABLESPACE 생성
- create temporary tablespace 테이블스페이스명 tempfile '파일경로' size 크기;
- TABLESPACE 확장
- alter tablespace 테이블스페이스명 add datafile '파일경로' size 크기;
- alter database datafile '파일경로' resize 크기;
- TABLESPACE 관리
- alter tablespace 테이블스페이스명 offline;
- alter tablespace 테이블스페이스명 online;
- alter tablespace 테이블스페이스명 rename datafile '원본파일경로' to '파일경로';
- TABLESPACE 삭제
- drop tablespace 테이블스페이스명 including contents and datafile cascade constraints;
- 문법
- CREATE TABLESPACE 테이블스페이스명
DATAFILE '파일경로1' SIZE integer [M/K], '파일경로2' SIZE integer [M/K]
[ MINIMUM EXTENT integer [M/K]]
[ BLOCKSIZE integer [K]] [ DEFAULT STORAGE (
INITIAL integer [M/K]
NEXT integer [M/K]
MAXEXTENTS integer
MINEXTENTS integer
PCTINCREASE integer)]
[ ONLINE | OFFLINE ]
[ PERMANENT | TEMPORARY ]
[ EXTENT MANAGEMENT [ DICTIONARY | LOCAL
[ AUTOALLOCATE | UNIFORM [ SIZE integer [M/K]]]]]
[ SEGMENT SPACE MANAGEMENT [ MANUAL | AUTO]] - OPEN 상태에서 DATAFILE 이동
- alter tablespace 테이블스페이스명 offline;
offline 된 T/S에 대해 복사/이동 후
alter tablespace 테이블스페이스명 rename datafile '파일경로' to '파일경로';
alter tablespace 테이블스페이스명 online; - MOUNT 상태에서 DATAFILE 이동
- startup mount;
해당 T/S에 대해 복사/이동 후
alter database rename file '파일경로' to '파일경로';
alter database open; - 모든 데이타 파일은 mount상태에서 복사/이동 가능
- system 파일은 mount상태에서만 복사/이동 가능
- >>Index<<
- TEMPORARY TABLESPACE
- TEMPORARY TABLESPACE 관리
- TEMPORARY T/S는 READ ONLY 설정 불가, nologgin 상태이며 rename불가, 복구대상이 아님
READ ONLY DATABASE 에서도 TEMPORARY 파일은 필요 - DEFAULT TEMPORARY TABLESPACE 확인
- select * from database_properties where property_name like '%TEMP%';
- TEMPORARY TABLESPACE 변경
- create temporary tablespace 테이블스페이스명_신 tempfile '파일경로' size 크기;
alter database default temporary tablespace 테이블스페이스명_신;
drop tablespace 테이블스페이스명_구; - >>Index<<
- UNDO TABLESPACE
- PARAMETER 설정 / 9i
- UNDO_MANAGEMENT = AUTO [ MANUAL ]
UNDO_TABLESPACE = UNDOTBS1
UNDO_SUPPRESS_ERRORS = TRUE // 10g 에서는 쓰이지 않음
UNDO_RETENTION = integer (초) - PARAMETER 확인 / 9i
- show parameter undo;
- DEFAULT UNDO TABLESPACE 설정
- alter system set undo_tablespace = 테이블스페이스명;
parameter 'UNDO_TABLESPACE' 수정 - 설정 조회
- select segment_name, owner, tablespace_name, status
from dba_rollback_segs; - >>Index<<
- DATABASE BUFFER CACHE
- DBWR 기동 이벤트
- Checkpoint - 일반적인 ckpt는 어디까지 내려썼는지만 확인 immediate ckpt시 즉시 내려씀
Dirty Block 임계값 도달
LRU List 의 Free Block 이 부족할 때
Time out
T/S offline (9i부터는 online시), read only, begin backup
Table Drop, Truncate
RAC ping - STANDARD BLOCK SIZE
- System과 Temporary tablespace는 스탠다드 사이즈만 사용 가능
- DB생성시 설정되는 표준 사이즈, 수정 불가(system T/S 가 이미 사용중이므로)
- show parameter db_block_size
- 사용 가능한 BLOCK SIZE 조회
- show parameter cache_size
- db_nk_cache_size / n = '2, 4, 8, 16, 32'
- DB_KEEP_CACHE_SIZE, DB_RECYCLE_CACHE_SIZE
- hit rate 향상을 위한 parameter
db_keep_cache_size : 자주 호출되는 data를 pinning 할 때 쓰임
db_recycle_cache_size : 차후 호출될 가능성의 희박한 data를 읽을 때 쓰임 - SGA 크기 조회
- show parameter sga
show parameter sga_max - nk BLOCK SIZE의 TABLESPACE 생성
- alter system set db_cache_size = 크기[M]; // SGA영역의 공간 확보를 위해 db_cache_size를 줄임
alter system set db_nk_cache_size = 크기[M]; // 줄여진 db_cache_size 만큼 할당 가능
create tablespace 테이블스페이스명 datafile '파일경로' size 크기 blocksize nk; - nk 블럭의 T/S가 존재하면 해당 db_nk_cache_size 를 0으로 설정 불가
- >>Index<<
- ROW MIGRATION / CHAINING
- migration 은 해소 가능 chaining 은 해소 불가
오라클은 이 두 가지 경우를 구분하지 않음 - TABLE 상태 확인
- select owner, table_name, tablespace_name from dba_tables
where owner = '유저명' and table_name = '테이블명'; - TABLE ANALYZE
- analyze table 스키마.테이블명 compute statistics;
- dictionary의 통계정보를 갱신시켜 주는 작업
- CHAIN COUNT 조회
- select num_rows, chain_cnt from dba_tables where table_name = '테이블명';
- TABLE 이동
- alter table 테이블명 move
[ tablespace 테이블스페이스명]; // 생략시 현재 사용중인 T/S 내에서 옮겨짐 - INDEX 조회
- select table_name, index_name, status from dba_indexes where table_name = '테이블명'
- INDEX REBUILD
- alter index 스키마.인덱스명 rebuild;
- TABLE MOVE 명령후 ROWID가 변경됐으므로 INDEX를 REBUILD 해주어야 함
- TABLE의 공간 사용량 조회
- select num_rows, blocks, empty_blocks, avg_space, avg_row_ren from dba_tables
where owner = '유저명' and table_name = '테이블명'; - BLOCKS : H/M 왼쪽 블럭 수
EMPTY_BLOCKS : 미사용 블럭 , H/M 오른쪽 블럭 수
AVG_SPACE : 사용중인 블럭의 평균 빈공간
AVG_ROW_LEN : row의 평균 길이 - TABLE의 EXTENT설정 조회
- select table_name, initial_extent, min_extents from dba_tables
where owner = '유저명' and table_name = '테이블명'; - TABLESPACE의 EXTENT설정 조회
- select tablespace_name, block_size, initial_extent, min_extents from dba_tablespaces
where tablespace_name = '테이블스페이스명'; - >>Index<<
- PARTITIONED TABLE
- LIST 분할
- create table table_name (column_1 type( ), column_2 type( ) ... )
partition by list (column_2) (
partition partition_name values ('value_1') tablespace tablespace_name,
partition partition_name values ('value_2') tablespace tablespace_name); - multi column partition 지원 안함
NULL 값 지정 가능, MAXVALUES 지정 불가
list를 구성하는 문자열은 4k 초과 불가 - PARTITIONED TABLE 조회
- select table_owner, table_name, partition_name, tablespace_name from dba_tab_partitions where table_owner = '유저명';
- TABLE의 PARTITION 여부 조회
- select owner, table_name, partitioned from dba_tables where owner = '유저명';
- PARTITION 관리
- alter table 테이블명 add partition partition_name values ('value') tablespacetablespace_name;
- alter table 테이블명 drop partition partition_name;
- RANGE 분할
- create table table_name (column_1 type( ), column_2 type( ) ... )
partition by range (column_2) (
partition partition_name values less than (value_1),
partition partition_name values less than (value_2),
partition partition_name values less than ( MAXVALUE ) ); - HASH 분할
- create table table_name (column_1 type( ), column_2 type( ) ... )
partition by hash (column_2)
partitions integer store in (tablespace_name, tablespace_name); - >>Index<<
- DEFERRED CONSTRAINTS
- 문법
- CREATE TABLE table_name (column_1 type( ), column_2 type ( ), ...
CONSTRAINT constraint_name constraint_type (column)
[ NOT DEFERRABLE | DEFERRABLE [ INITIALLY [ IMMEDIATE | DEFERRED ]]]); - 지연된 제약조건 활성화
- ALTER SESSION SET CONSTRAINTS = [ IMMEDIATE | DEFERRED | DEFAULT ]
- >>Index<<
- USER
- USER 생성
- create user 유저명 identified by 패스워드
default tablespace 테이블스페이스명
temporary tablespace 임시테이블스페이스명
quota integer [M] on 유저명; - USER 변경
- alter user 유저명 identified by 패스워드
default tablespace 테이블스페이스명
temporary tablespace 임시테이블스페이스명
quota integer [M] on 유저명
[ password expire ]; - USER 의 TABLESPACE 할당량 조회
- select * from dba_ts_quotas;
- >>Index<<
- PROFILE
- PROFILE 조회
- select distinct profile from dba_profiles;
- USER 의 PROFILE 조회
- select username, profile from dba_users;
- PROFILE 생성
- create profile profile_name limit
제한사항 value 제한사항 value ... ; - PROFILE 적용
- alter user 유저명 profile profile_name;
- PARAMETER 'resource_limit' 의 값이 TRUE로 설정되어 있어야 함
- >>Index<<
- PRIVILEGES
- 권한 부여 / SYSTEM PRIVS
- grant 권한 to 유저명
[ with admin option ]; - 권한 부여 / OBJECT PRIVS
- grant 권한 on 개체 to 유저명
[ with grant option ]; - 권한 조회
- select * from dba_sys_privs where grantee like '유저명';
- GRANT 조회 / TABLE
- select * from all_tab_privs where table_name = '테이블명';
- 권한 취소 / SYSTEM PRIVS
- revoke 권한 from 유저명;
- 권한 취소 / OBJECT PRIVS
- revoke 권한 on 개체 from 유저명;
- >>Index<<
- ROLE
- ROLE 의 PRIVS 조회
- select * from dba_sys_privs where grantee = 'role_name';
- ROLE 생성
- create role role_name;
- ROLE 에 SYSTEM PRIVS 부여
- grant privs_name to role_name;
- ROLE 에 OBJECT PRIVS 부여
- grant privs_name on 개체 to role_name;
- DEFAULT ROLE 지정
- alter user user_name default role role_name;
- ROLE 활성화
- set role role_name;
- set role all;
- ROLE 조회
- select * from session_roles;
- >>Index<<
- EXPORT
- 문법
- ]$ exp username/passwd option=(value1, value2, ... ) option=value ...
- OPTION
- file: 백업 파일명 지정 (default : expdat.dmp)
- rows: 테이블의 row의 포함 여부 지정
- full: 전체 DB에 대한 익스포트 지정
- owner: 익스포트할 사용자 지정 (사용자모드)
- table: 익스포트할 테이블 지정 (테이블모드)
- tablespace: 익스포트할 테이블스페이스 지정 (T/S 모드)
- inctype: 전체 백업 레벨 지정 (8i까지만 사용됨)
- indexes: 인덱스 익스포트 지정
- full, owner, table, tablespace 는 동시 사용 불가
- 익스포트시 sys로 작업은 지양 (dictionary data까지 포함되므로)
- >>Index<<
- IMPORT
- 문법
- ]$ imp username/passwd option=(value1, value2, ... ) option=value ...
- OPTION
- file: 입력 파일명 지정
- ignore: 임포트 실행중 입력 오류 무시
- rows: 테이블의 row의 포함 여부 지정
- full: 전체 DB에 대한 임포트트 지정
- fromuser: 익스포트된 객체를 소유한 사용자중 임포트 대상이 되는 사용자
- touser: 임포트할 대상이 되는 사용자
- table: 임포트할 테이블 지정
- tablespace: 임포트할 테이블스페이스 지정
- 임포트 작업시 실행 순서 : 새로운 테이블생성 / 데이터 입력, 인덱스 리빌드 / 제약조건 활성화
- >>Index<<
- DIRECT LOAD
- DIRECT LOAD SAMPLE
- sample.ctl
LOAD DATA INFILE * INTO TABLE table_name
FIELDS TERMINATED BY ',' (column1, column2, column3)
BEGINDATA
111,aa,95
112,ab,86
...
...
- ]$ sqlldr username/passwd sample.ctl
- >>Index<<
- ORACLE NET / HOST NAMING
- HOST NAMING
- port 번호등의 정보를 Client에게 제공하지 않음
다수의 DB를 운용하는 경우는 사용할 수 없음
GLOBAL_DBNAME은 되도록이면 도메인 형식을 사용
(호스트명만 기입시 Windows Client 에서만 이용가능) - SERVER 설정 / LINUX
- $ORACLE_HOME/network/admin/listener.ora
- ora10g =
- (ADDRESS_LIST =
- (ADDRESS = (PROTOCOL = TCP) (HOST = xxx.xxx.xxx.xxx) (PORT = 1521))
- )
- SID_LIST_ora10g =
- (SID_LIST =
- (SID_DESC = (GLOBAL_DBNAME = ora10g.xxx.xxx)
- (ORACLE_HOME = /app/ora10g/10g)
- (SID_NAME = DB09)
- )
- )
- LISTENER 구동
- ]$ lsnrctl start ora10g
- CLIENT 설정 / WINDOWS
- GLOBAL_DBNAME 으로 ping이 되는지 확인, 필요시 hosts나 DNS에 등록
- %ORACLE_HOME%\network\admin\sqlnet.ora
- SQLNET.AUTHENTICATION_SERVICES= (NTS)
- NAMES.DIRECTORY_PATH= (HOSTNAME)
- C:\>sqlplus username/passwd@ora10g.xxx.xxx
- CLIENT 설정 / LINUX
- GLOBAL_DBNAME 으로 ping이 되는지 확인, 필요시 hosts나 DNS에 등록
- $ORACLE_HOME/network/admin/sqlnet.ora
- NAMES.DIRECTORY_PATH= (HOSTNAME)
- ]$ sqlplus username/passwd@ora10g.xxx.xxx
- >>Index<<
- ORACLE NET / LOCAL NAMING
- LOCAL NAMING
- port 번호등 서버정보를 Client가 가지고 있음
- SERVER 설정 / LINUX
- $ORACLE_HOME/network/admin/listener.ora
- ora10g =
- (ADDRESS_LIST =
- (ADDRESS = (PROTOCOL = TCP) (HOST = xxx.xxx.xxx.xxx) (PORT = 1521))
- )
- SID_LIST_ora10g =
- (SID_LIST =
- (SID_DESC = (ORACLE_HOME = /app/ora10g/10g)
- (SID_NAME = DB09)
- )
- )
- 다수의 DB가 존재 할 경우 각 DB의 listner port번호는 다르게 설정한다
- LISTENER 구동
- ]$ lsnrctl start ora10g
- 각각의 DB에 해당하는 listener.ora 파일을 생성하고 listener를 각각 구동한다
- CLIENT 설정 / NAMES.DEFAULT_DOMAIN 미설정 시
- sqlnet.ora
- NAMES.DIRECTORY_PATH= (TNSNAMES)
- tnsnames.ora
- ora9i =
- (DESCRIPTION =
- (ADDRESS = (PROTOCOL = TCP) (HOST = xxx.xxx.xxx.xxx) (PORT = 1529))
- (CONNECT_DATA = (SID = DB09))
- )
- ora10g =
- (DESCRIPTION =
- (ADDRESS = (PROTOCOL = TCP) (HOST = xxx.xxx.xxx.xxx) (PORT = 1521))
- (CONNECT_DATA = (SID = DB10))
- )
- ]$ sqlplus username/passwd@ora10g
]$ sqlplus username/passwd@ora9i - CLIENT 설정 / NAMES.DEFAULT_DOMAIN 설정 시
- TCP/IP 에서의 DOMAIN과 관계 없음
- sqlnet.ora
- NAMES.DEFAULT_DOMAIN= webdb.co.kr
- NAMES.DIRECTORY_PATH= (TNSNAMES)
- tnsnames.ora
- ora9i.webdb.co.kr =
- (DESCRIPTION =
- (ADDRESS = (PROTOCOL = TCP) (HOST = xxx.xxx.xxx.xxx) (PORT = 1529))
- (CONNECT_DATA = (SID = DB09))
- )
- ora10g.webdb.co.kr =
- (DESCRIPTION =
- (ADDRESS = (PROTOCOL = TCP) (HOST = xxx.xxx.xxx.xxx) (PORT = 1521))
- (CONNECT_DATA = (SID = DB10))
- )
- ]$ sqlplus username/passwd@ora10g
]$ sqlplus username/passwd@ora9i
]$ sqlplus username/passwd@ora10g.webdb.co.kr - >>Index<<
- DATABASE 생성 / 9i
- ENV CHECK
- ]$ env | grep ORACLE
- 기존 파일 삭제
- $ORACLE_BASE/oradata/
$ORACLE_BASE/admin/$ORACLE_SID/ - PARAMETER FILE 편집
- $ORACLE_HOME/dbs/initSID_name.ora
- DB 생성
- createdb.sql
- CREATE DATABASE $ORACLE_SID
- LOGFILE
- GROUP 1 ('$ORACLE_BASE/oradata/disk4/redo01.log') size 1M,
- GROUP 2 ('$ORACLE_BASE/oradata/disk4/redo02.log') size 1M,
- GROUP 3 ('$ORACLE_BASE/oradata/disk4/redo03.log') size 1M
- MAXLOGFILES 5
- MAXLOGMEMBERS 5
- MAXDATAFILES 100
- DATAFILE
- '$ORACLE_BASE/oradata/disk3/system01.dbf' size 300M
- EXTENT MANAGEMENT LOCAL
- UNDO TABLESPACE undo DATAFILE
- '$ORACLE_BASE/oradata/disk3/undo01.dbf' size 10M
- DEFAULT TEMPORARY TABLESPACE temp TEMPFILE
- '$ORACLE_BASE/oradata/disk3/temp01.dbf' size 10M
- CHARACTER SET KO16KSC5601
- ;
- @$ORACLE_HOME/rdbms/admin/catalog.sql
- @$ORACLE_HOME/rdbms/admin/catproc.sql
- conn system/manager;
- @$ORACLE_HOME/sqlplus/admin/pupbld.sql
- ]$ sqlplus '/as sysdba'
SQL> startup nomount
SQL> @createdb.sql - >>Index<<
- DATABASE 생성 / 10g
- ENV CHECK
- ]$ env | grep ORACLE
- 기존 파일 삭제
- $ORACLE_BASE/oradata/
$ORACLE_BASE/admin/$ORACLE_SID/ - PARAMETER FILE 편집
- $ORACLE_HOME/dbs/initSID_name.ora
- DB 생성
- createdb.sql
- CREATE DATABASE $ORACLE_SID
- LOGFILE
- GROUP 1 ('$ORACLE_BASE/oradata/disk4/redo01.log') size 4M,
- GROUP 2 ('$ORACLE_BASE/oradata/disk4/redo02.log') size 4M,
- GROUP 3 ('$ORACLE_BASE/oradata/disk4/redo03.log') size 4M
- MAXLOGFILES 5
- MAXLOGMEMBERS 5
- MAXDATAFILES 100
- DATAFILE
- '$ORACLE_BASE/oradata/disk3/system01.dbf' size 300M
- EXTENT MANAGEMENT LOCAL
- SYSAUX DATAFILE
- '$ORACLE_BASE/oradata/disk3/sysaux01.dbf' size 200M
- UNDO TABLESPACE undo DATAFILE
- '$ORACLE_BASE/oradata/disk3/undo01.dbf' size 10M
- DEFAULT TEMPORARY TABLESPACE temp TEMPFILE
- '$ORACLE_BASE/oradata/disk3/temp01.dbf' size 10M
- CHARACTER SET KO16KSC5601
- ;
- @$ORACLE_HOME/rdbms/admin/catalog.sql
- @$ORACLE_HOME/rdbms/admin/catproc.sql
- conn system/manager;
- @$ORACLE_HOME/sqlplus/admin/pupbld.sql
- ]$ sqlplus '/as sysdba'
SQL> startup nomount
SQL> @createdb.sql - >>Index<<
- ARCHIVE LOG MODE
- DB 종료
- SQL> shutown immediate
- Parameter File 수정
- log_archive_start = true
- log_archive_dest = destination
- log_archive_format = %S.arc
- 다수의 아카이빙
- log_archive_duplex_dest = destination
- log_archive_min_succed_dest = [ 1 | 2 ]
- log_archive_dest_# = "location = destination"
- log_archive_dest_# = "service = tnsname"
- DB 기동 / 아카이브 모드 변경
- SQL> startup mount
SQL> alter database archivelog; SQL> startup open - 아카이브 모드 확인 후 Close Backup
SQL> archive log list - >>Index<<
Boss 설정하기
# jboss설치
-http://labs.jboss.com/ 에서 최근버전을 받아서 압축을 푼다
-자바 환경변수는 1.5버전을 추천한다.
-JBOSS_HOME/bin/run.bat 실행 후 http://localhost:8080/으로 확인한다.
-JBOSS_HOME/server/default/deploy/jbossweb-tomcat55.sar/root.war 이 경로가 디폴트로 보여진다.
# jboss deploy 폴더 설정
-JBOSS_HOME/server/default/conf/jboss-service.xml의 아래 예시와 같이 콤마(,)를 구분자로 하여 배포파일 또는 폴더를 추가한다.
-디폴트는 deploy/ 폴더이고 경로의 끝에 슬래쉬(/)를 붙이면 폴더로 인식한다.
-주의할 점은 jar, war, ear같은 파일뒤에 슬래쉬를 붙이면 deploy 되지 않지만 JBOSS_HOME/server/default/deploy폴더 속에 aaa.jar 과 같은 이름의 폴더는 deploy 가능하다.
<attribute name="URLs">
deploy/,
file:///D:/aa/bbb/ccccejb.jar
</attribute>
# jboss 오라클 드라이버 설정
-ojdbc14.zip를 JBOSS_HOME/server/default/lib 폴더에 복사
-JBOSS_HOME/docs/examples/jca/oracle-ds.xml을 JBOSS_HOME/server/default/deploy 폴더에 복사
-oracle-ds.xml를 아래와 같이 수정
<local-tx-datasource>
<jndi-name>oracle</jndi-name>
<connection-url>jdbc:oracle:thin:@127.0.0.1:1521:orcl(일반적으로)</connection-url>
<driver-class>oracle.jdbc.driver.OracleDriver</driver-class>
<user-name>xxx</user-name>
<password>yyy</password>
<exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.OracleExceptionSorter</exception-sorter-class-name>
<metadata>
<type-mapping>Oracle9i</type-mapping>
</metadata>
</local-tx-datasource>
-jboss를 restart하면 콘솔에서
[WrapperDataSourceService] Bound ConnectionManager 'jboss.jca:service=DataSourceBinding,name=oracle' to JNDI name 'java:oracle'
메시지 확인 가능
-WEB-INF/web.xml 수정
<resource-ref>
<res-ref-name>jdbc/oracle</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
-WEB-INF/jboss-web.xml
<resource-ref>
<res-ref-name>jdbc/oracle</res-ref-name>
<jndi-name>java:oracle</jndi-name>
</resource-ref>
# 기타 라이브러리 추가
ojdbc.jar 파일 등
서비스시 필요한 라이브러리는 JBOSS_HOME/server/default/lib 폴더에 복사한다
# 서비스 루트 설정
WEB-INF/jboss-web.xml 아래 소스 추가 또는 수정
<context-root>/</context-root>
# 서비스 설정이 되었다면 이클립스로 가서 유저 라이브러리를 설정해 ejb를 사용해 보자.
이클립스를 실행하고 환경설정에 가서 JAVA 항목으로 간다.
두번째 유저 라이브러리 항목을 설정하고 EJB 라는 이름을 라이브러리를 만든다.
그리고 필요한 jar 파일을 가져오자.
\server\qnsolv\deploy\ oracle-ds.xml 파일 생성한다.
<?xml version="1.0" encoding="UTF-8"?>
<datasources>
<local-tx-datasource>
<jndi-name>jdbc.dsCizle</jndi-name>
<connection-url>jdbc:oracle:thin:@xxx.xxx.xxx.xxx:1521:HEAVEN</connection-url>
<driver-class>oracle.jdbc.driver.OracleDriver</driver-class>
<user-name>user_xxx</user-name>
<password>user_xxx00</password>
<min-pool-size>10</min-pool-size>
<max-pool-size>100</max-pool-size>
<blocking-timeout-millis>5000</blocking-timeout-millis>
<idle-timeout-minutes>15</idle-timeout-minutes>
<exception-sorter-class-name>org.jboss.resource.adapter.jdbc.vendor.OracleExceptionSorter</exception-sorter-class-name>
<metadata>
<type-mapping>Oracle9i</type-mapping>
</metadata>
</local-tx-datasource>
</datasources>
jsp 소스
<%@page import="javax.transaction.Transaction"%>
<%@page import="javax.transaction.TransactionManager"%>
<%@page import="javax.transaction.UserTransaction"%>
<%@page import="java.sql.ResultSet"%>
<%@page import="java.sql.Statement"%>
<%@ page import="java.sql.Connection"%>
<%@ page import="javax.sql.DataSource"%>
<%@ page import="javax.naming.Context"%>
<%@ page import="javax.naming.InitialContext"%>
oracle test<br>
<%
Connection con=null;
Connection conmysql=null;
InitialContext ctx=null;
DataSource datasource=null;
TransactionManager tm=null;
ResultSet rs=null;
Statement stmt=null;
try {
ctx = new InitialContext();
tm = (TransactionManager)ctx.lookup("java:/TransactionManager");
tm.begin();
datasource = (DataSource) ctx.lookup("java:/jdbc.dsCizle");
out.println("<br>datasource==" + datasource);
con = datasource.getConnection();
out.println("<br>tm="+tm);
stmt = con.createStatement();
rs = stmt.executeQuery("select count(*) cnt from aa");
while(rs.next()){
out.println("<br/>start cnt="+rs.getString("cnt")+"<br/>");
}
stmt.executeUpdate("insert into aa(a) values(1)");
out.println("<br>after insert date<br>");
rs = stmt.executeQuery("select count(*) cnt from aa");
while(rs.next()){
out.println("insert cnt="+rs.getString("cnt"));
}
rs = stmt.executeQuery("select a from aa");
while(rs.next()){
out.println("<br>"+rs.getString("a"));
}
out.println("<br>");
tm.rollback();
rs = stmt.executeQuery("select count(*) cnt from aa");
while(rs.next()){
out.println("rollback cnt="+rs.getString("cnt"));
}
out.println("<br>after rollback date");
rs = stmt.executeQuery("select a from aa");
while(rs.next()){
out.println("<br>"+rs.getString("a"));
}
} catch (Exception e) {
try{
con.close();
ctx.close();
tm.rollback();
}catch(Exception e2){
}
e.printStackTrace();
}
%>
Windows에서 MySQL 설치하기
|
Windows에서는 MSI(Microsoft Windows Installer)를 사용한다. Windows 2000 / XP / 2003 Server에서 사용할 수 있으며, http://dev.mysql.com/downloads/mysql/5.0.html에서 다운로드받을 수 있다("Windows Downloads"로 검색하라). 필수 설치 파일을 받았다면 더블클릭하여 실행한다.
다음 설명은 Windows용 MySQL 5.0.22 기준이다. 설치 과정은 Windows 환경에는 독립적이다.
[노트]
MSI 형식 이외의 설치 방법도 제공한다. "Complete Package" 방식과 "Noinstall Archive" 방식이 그것이다. "Essentials Package" 이외의 방법을 사용한다면 MySQL 매뉴얼을 반드시 읽어보아야 한다. 매뉴얼은 http://dev.mysql.com/doc/refman/5.0/en/windows-choosing-package.html에서 구할 수 있다.
본격적으로 설치를 시작해보자(MySQL AB 웹 사이트에서 MSI 파일을 다운로드했다고 가정한다).
1. MSI 파일을 더블클릭한다. [그림 2-4]와 같은 화면이 나오면 [Next] 버튼을 누른다.
[그림 2-4] Windows용 설치 마법사 시작 화면
2. "Typical", "Complete" 또는 "Custom" 중에 하나를 선택한다([그림 2-5] 참조). "Custom"은 MySQL의 구성 요소들을 선택적으로 설치할 수 있다. "Complete"는 MySQL의 모든 요소를 설치한다. 즉, 문서에서 벤치마킹까지 MySQL 전체를 설치한다. "Typical"은 클라이언트와 서버 그리고 일반적으로 필요한 도구들을 설치해준다. 대부분의 사용자들에게는 "Typical"이 적당하므로 "Typical"을 선택하고 [Next] 버튼을 클릭한다.
[그림 2-5] 설치 유형을 선택한다.
3. 앞서 선택했던 것을 다시 확인하고 [Install] 버튼을 클릭하면 설치가 시작된다.
[노트]
설치를 하다보면 MySQL.com 계정이 필요할 것이다. 이 계정은 여러분이 설치하고 있는 데이터베이스와는 전혀 관련이 없다. 단지 MySQL.com 웹 사이트의 계정일 뿐이다. 계정을 가지고 있지 않다면 계정을 생성해야 한다. 참고로 이런 등록 절차는 생략할 수 있다.
4. 설치가 완료되면 "MySQL Configuration Wizard"를 설치할 것인지 묻는다. 이 마법사는 반드시 설치해야 한다. 왜냐하면, 여러분의 필요에 맞게 my.ini 파일을 생성해주기 때문이다. "MySQL Configuration Wizard"를 설치하기 위해서 "Configure the MySQL Server Now" 체크 상자를 선택하자([그림 2-6] 참조).
[그림 2-6] MySQL 설치 후 Configuration Wizard를 설치하는 것이 좋다.
5. "MySQL Configuration Wizard"가 실행되면 간단한 환영 메시지가 나온다. [Next] 버튼을 클릭하면 "Detailed"와 "Standard" 설치 방법 중에 하나를 선택할 수 있다. 우리는 가능한 옵션을 모두 확인하기 위해서 "Detail" 방식을 선택할 것이다. "Standard" 방식을 선택할 경우, 설정 변경을 하려면 직접 my.ini 파일을 수정해야 한다. "Detailed" 라디오 버튼을 선택하고 [Next] 버튼을 클릭한다.
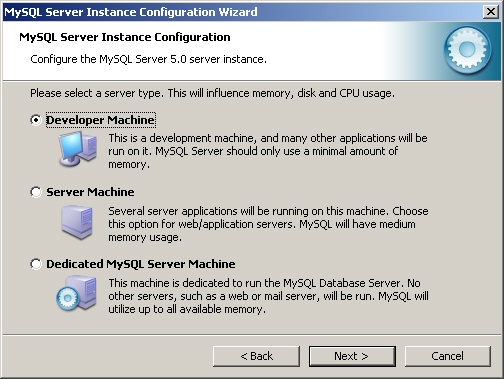
6. 다음 단계는 서버 머신 타입을 결정한다. [그림 2-7]과 같이 "Developer Machine", "Server Machine", "Dedicated MySQL Server Machine"을 선택할 수 있다. 서버 머신 타입에 따라서 메모리, 디스크, 프로세서의 할당이 달라진다. 개인 컴퓨터에서 테스트 목적으로 MySQL을 설치한다면 "Developer Machine"을 선택해야 한다. 서버용 머신에서 다른 서버와 함께 MySQL을 설치하려면 "Server Machine"을 선택해야 한다. MySQL을 위한 전용 서버 머신이 준비된 경우라면 "Dedicated MySQL Server Machine"을 선택하는 것이 좋다. 이 경우 대부분의 시스템 자원을 MySQL에 할당해준다.
[그림 2-7] 서버 머신 타입의 설정
7. 다음 설정은 데이터베이스 사용에 대한 것이다. "Multifunctional Database"는 InnoDB와 MyISAM 엔진에 균등하게 자원을 배분한다. "Transaction Database"는 InnoDB와 MyISAM 엔진을 모두 사용할 수 있지만, InnoDB에 대부분의 자원을 할당한다. "Non-Transactional Database"는 MyISAM 엔진에 모든 자원을 할당한다. 즉, InnoDB는 사용할 수 없다. 여러분의 사용 패턴을 확신할 수 없다면 "Multifunctional Database"를 선택하는 것이 좋다.
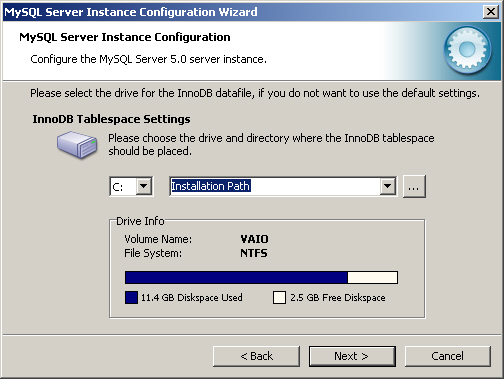
8. InnoDB 저장 엔진이 활성화되었다면 [그림 2-8]과 같이 저장 관련 정보를 설정해야 한다. [그림 2-8]은 초기 설정 상태이다. 원한다면 설정을 바꿔도 좋다. [Next] 버튼을 클릭하면 다음 단계로 넘어간다.
[그림 2-8] InnoDB 저장 엔진을 위한 디스크 튜닝
9. MySQL 서버의 동시 접속수를 지정한다. 동시 접속수는 데이터베이스의 사용 패턴과 트래픽 정도에 따라서 달라져야 한다. "Decision Support (DSS)/OLAP"이 기본 설정이다. 기본 설정은 최대 100개의 동시 접속을 허용하며, 평균적으로 20개의 동시 접속이 있다고 가정한다. "Online Transaction Processing(OLTP)"은 최대 500개의 동시 접속을 허용한다. "Manual Setting"은 여러분이 직접 동시 접속수를 지정할 수 있도록 해준다. 동시 접속에 대한 결정을 했다면 [Next] 버튼을 클릭한다.
10. 다음은 네트워크 옵션 설정이다. TCP/IP 사용여부와 포트를 지정할 수 있다. 기본 포트는 3306이지만, 다른 포트(사용중이지 않은 포트)로 변경할 수 있다. TCP/IP 이외에 "Enable Strict Mode" 사용여부도 지정할 수 있다. "Strict Mode"가 무엇인지 잘 모르겠다면 "Enable Strict Mode"를 선택된 상태로 두는 것이 좋다. 좀 더 자세한 정보가 필요하다면http://dev.mysql.com/doc/refman/5.0/en/server-sql-mode.html을 방문해보자. 모든 선택이 끝났다면 [Next] 버튼을 클릭한다.
[노트]
TCP/IP 설정에서 지정한 포트를 위해 방화벽 수정이 필요하다. 즉, 3306포트(직접 포트를 지정했다면 다를 수 있다)를 위한 방화벽 흐름제어가 필요하다.
11. 다음은 문자세트을 지정한다. 기본 옵션은 "Standard Character Set"으로 "Latin1"을 사용한다. "Best Support for Mulilingualism"은 UTF8을 사용한다. UTF8은 하나의 문자세트로 다국어를 표현할 수 있다. "Manual Selected Default Character Set"은 직접 문자세트를 선택할 수 있게 해준다. 이 항목을 선택하면 적당한 문자 세트를 선택할 수 있도록 드롭다운 리스트가 나온다. 설정을 마쳤으면 [Next] 버튼을 클릭한다.
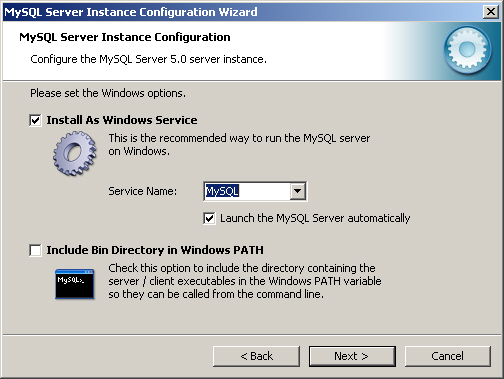
12. MySQL은 서비스 형태로 설치하는 것이 좋다. [그림 2-9]는 이와 관련된 설정 화면이다. "Install As Windows Service" 체크 상자를 체크하고 서비스 이름을 선택한다. 원한다면 "Launch the MySQL Server Automatically"를 체크해도 좋다. 참고로, MySQL의 bin 폴더를 Windows PATH 환경변수에 추가하면 cmd 창에서 MySQL를 쉽게 접근할 수 있다. 설정을 마쳤으면 다음으로 넘어간다.
[그림 2-9] MySQL 서버 인스턴스 설정
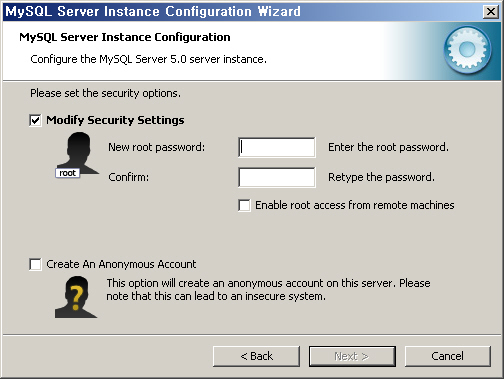
13. 다음은 보안 옵션에 대한 설정으로 가장 중요하다. [그림 2-10]과 같이 root 암호를 지정한다. 암호를 두 번 입력하여 오타 여부를 다시 확인한다. "Enable Root Access"는 의미를 잘 알고 있는 경우에만 선택하는 것이 좋다. 일반적으로 root 접근은 로컬로 제한하는 것이 보통이다. 익명 접근을 허용할 수도 있지만 추천하지는 않는다. 보안에 좋지 않기 때문이다. 설정을 마쳤으면 [Next] 버튼을 클릭한다.
[그림 2-10] root 암호를 지정한다.
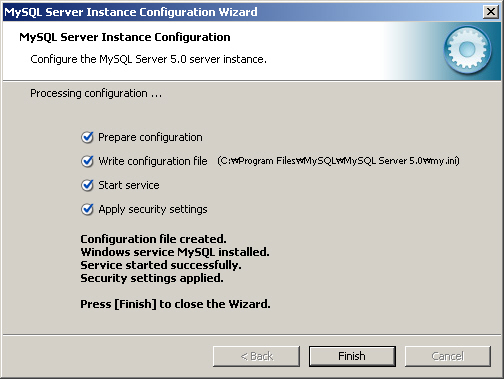
14. 이제 마지막 단계이다. [Execute] 버튼을 클릭하면 화면에 나열된 순서대로 처리를 시작한다. 모든 처리가 끝나면 [그림 2-11]과 같은 화면을 볼 수 있다.
[그림 2-11] MySQL Configuration Wizard의 성공적인 종료
"MySQL Configuration Wizard"는 my.ini 설정 파일을 "C:\Program Files\MySQL\MySQL Server 5.0\"에 만들고 MySQL 서비스를 시작시켜 주는 것으로 인스톨 및 설정 과정을 마무리한다.
[팁]
my.ini 파일을 직접 수정하는 것도 가능하다. 수정 후에는 반드시 MySQL 서버를 다시 시작해야 한다.
Introduction
MySQL 클러스터는 분산 컴퓨팅 환경에서 high-availability와 high-redundancy를 채택하였다. MySQL 클러스터는 NDB 클러스터 스토리지 엔진을 사용하여, 클러스터에서 여러 개의 서버가 함께 돌아가도록 한다. MySQL 클러스터가 지원하는 운영 체제는 Linux, Mac OS X, Solaris 등 이다. 더 자세한 정보는 다음 사이트를 참고 하길 바란다. http://www.mysql.com/products/cluster
MySQL Cluster Overview
MySQL 클러스터는 share-nothing 시스템에서 in-memory 데이터 베이스의 클러스터링을 가능하게 한다. 이러한 아키텍쳐는 특정한 하드웨어 및 소프트웨어를 요구하지 않으므로 비용을 절감할 수 있도록 하며, 각 콤포넌트가 고유 메모리와 디스크를 보유함으로 단일 취약점(single point of failure)을 가지지 않는다.
MySQL 클러스터는 일반 MySQL 서버에 NDB라는 스토리지 엔진을 통합하여, 다음 그림과 같이 MySQL서버, NDB 클러스터의 데이터 노드, MGM 서버가 포함된 컴퓨터와 데이터에 접근하기 위한 어플리케이션 프로그램으로 구성된다.
데이터가 NDB 클러스터 스토리지 엔진에 저장될 때, 테이블은 데이터 노드에 저장된다. 각 테이블은 클러스터의 MySQL 서버에서 직접 접근이 가능하다. 그래서 클러스터의 어떤 정보를 업데이트 하면, 다른 모든 MySQL서버에서 곧바로 확인할 수 있다.
MySQL 클러스터의 데이터 노드에 저장된 데이터는 미러링이 가능하며, 클러스터는 트랜잭션 중단 등 각 노드들의 상태에 대한 핸들링이 가능하다.

Basic MySQL Cluster Concepts
NDB는 높은 가용성과 데이터 지속성을 갖는 인 메모리 스토리지 엔진이다. DB 스토리지 는 failover와 로드 밸런싱 옵션을 설정할 수 있다. MySQL클러스터는 NDB 스토리지 엔진과 MySQL 서버로 구성되어 있으며, MySQL 클러스터의 클러스터 부분은 MySQL 서버에 독립적이다. MySQL 클러스터의 각 부분은 노드로 간주한다.
"노드"는 일반적으로 컴퓨터를 지칭하지만 MySQL 클러스터에서는 "프로세스"를 말한다.
클러스터 노드에는 세 가지 타입이 있으며, MySQL Cluster를 구성하기 위해 최소한 노드 세 개가 있어야 한다.
- MGM node : 이 노드는 설정을 포함, 다른 노드를 관리하는 매니저 노드이다. 다른 노드보다 가장 먼저 실행되며 ndb_mgmd 명령으로 실행시킨다.
- data node : 클러스터의 데이터를 저장하는 노드이다. ndbd 명령으로 실행시킨다.
- SQL node : 클러스터 데이터에 접근하는 노드이다. MySQL 클러스터에서는 NDB 클러스터 스토리지 엔진을 사용하는 MySQL 서버가 클라이언트 노드이다. mysqld --ndbcluster나 mysqld 명령으로 실행시키는데, 이 때는 my.cnf 에 ndbcluster를 추가한다.
Simple Multi-Computer How-To
다음과 같이 4대의 컴퓨터로 클러스터를 구성하는 것을 가정하고 있다. (4개의 노드로 구성되고, 각각의 노드는 편이성을 위해 IP로 지칭한다.)
아래에서 필요한 컴퓨터는 리눅스가 설치된 인텔 기반 데스크탑 PC이며, 4대 모두 동일한 이더넷 카드(100Mbps나 1기가 비트)가 필요하다.
Node IP Address
Management (MGM) node 192.168.0.10
MySQL server (SQL) node 192.168.0.20
Data (NDBD) node "A" 192.168.0.30
Data (NDBD) node "B" 192.168.0.40

설치 및 사용 시 주의할 점은 MySQL 클러스터는 클러스터 노드 간 커뮤니케이션에 암호화 및 보호 장치가 전혀 없으므로, 웹 상에서 사용하려면 방화벽을 사용하는 등의 보안상의 대책이 필요하다는 것이다.
MySQL Cluster를 사용하기 위해서는 -max 버전을 설치해야 한다. 모든 설치는 root권한으로 진행하며 작업에 필요한 파일은 /usr/local/ 에 저장한다.
1. /etc/passwd 와 /etc/group 파일에서 mysql 그룹과 유저가 있는지 확인한 후 없으면 다 음과 같이 생성한다.
# cd /usr/local # groupadd mysql # useradd -g mysql mysql
2. 유저와 그룹 생성 후 압축을 풀고, 심볼릭 링크를 걸어준다.
# tar -xzvf mysql-max-4.1.13-pc-linux-gnu-i686.tar.gz # ln -s /usr/local/ mysql-max-4.1.13-pc-linux-gnu-i686 mysql
3. mysql 디렉토리로 이동하여 시스템 데이터베이스 생성을 위한 스크립트를 실행시킨다.
# cd mysql # scripts/mysql_install_db --user=mysql
4. MySQL 서버와 데이터 디렉토리의 퍼미션을 설정한다.
# chown -R root . # chown -R mysql data # chgrp -R mysql .
5. 시스템 부팅 시 자동적으로 Mysql을 실행할 수 있도록 설정한다.
# cp support-files/mysql.server /etc/rc.d/init.d/ # chmod +x /etc/rc.d/init.d/mysql.server # chkconfig --add mysql.server
6. MGM (management) 노드를 별도의 PC에 설치할 경우 mysql 데몬은 설치하지 않아도 무방하다. 위와 같이 설치한 후 MGM 서버는 다음과 같이 설치를 계속한다.
# cd /usr/local/mysql/bin/ # cp ndb_mgm* /usr/local/bin/ # chmod +x ndb_mgm*
7. 각 데이터 노드와 SQL 노드는 MySQL서버 옵션과 connectstring에 대한 정보가 포함된 my.cnf파일이 필요하고, MGM노드는 config.ini 파일이 필요하다. 에디터를 열어 다음과 같이 편집한 후 파일을 저장한다.
# vi /etc/my.cnf [MYSQLD] # Options for mysqld process: Ndbcluster # run NDB engine ndb-connectstring=192.168.0.10 # location of MGM node [MYSQL_CLUSTER] # Options for ndbd process: ndb-connectstring=192.168.0.10 # location of MGM node
8. MGM 노드의 설정 파일을 만들기 위해 적당한 디렉토리를 만든 후 에디터를 열어 다음과 같이 편집한다.
# mkdir /var/lib/mysql-cluster
# cd /var/lib/mysql-cluster
# vi config.ini
[NDBD DEFAULT] # Options affecting ndbd processes on all data nodes:
NoOfReplicas=2 # Number of replicas
DataMemory=80M # How much memory to allocate for data storage
IndexMemory=18M # How much memory to allocate for index storage
# For DataMemory and IndexMemory, we have used the
# default values. Since the "world" database takes up
# only about 500KB, this should be more than enough
# for this example Cluster setup.
[TCP DEFAULT] # TCP/IP options:
portnumber=2202 # This the default; however, you can use any
# port that is free for all the hosts in cluster
# Note: In MySQL 5.0, this parameter is deprecated;
# it is recommended that you do not specify the
# portnumber at all and simply allow the port to be
# allocated automatically
[NDB_MGMD] # Management process options:
hostname=192.168.0.10 # Hostname or IP address of MGM node
datadir=/var/lib/mysql-cluster # Directory for MGM node logfiles
[NDBD] # Options for data node "A":
# (one [NDBD] section per data node)
hostname=192.168.0.30 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's
# datafiles
[NDBD] # Options for data node "B":
hostname=192.168.0.40 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's
# datafiles
[MYSQLD] # SQL node options:
hostname=192.168.0.20 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for SQL node's datafiles
# (additional mysqld connections can be
# specified for this node for various
# purposes such as running ndb_restore)
설치와 설정 과정이 끝났다. 이제 실행을 해 보자.
클러스터 노드들은 각각 실행되어야 한다. 실행 순서는 매니지먼트 노드를 가장 먼저 실행할 것을 권한다. 그 다음은 스토리지 노드와 SQL노드 순이다.
1. 매니지먼트 호스트에서 MGM 노드 프로세스를 실행시켜 보자. 컨피그레이션 파일을 찾을 수 있도록 -f 옵션을 주도록 한다.
# ndb_mgmd -f /var/lib/mysql-cluster/config.iniMGM 노드를 다운시킬 때에는 다음과 같이 하면 된다.
# ndb_mgm -e shutdown
2. 다음으로 데이터 노드 호스트에서 NDBD프로세스를 실행시킨다. --initial 이란 인수는 ndbd를 처음 실행할 때와 컨피그레이션이 바뀐 후 재시작 할 때만 사용한다.
# ndbd --initial
3. SQL 노드는 다음과 같이 mysql.server를 실행시킨다.
# /etc/rc.d/init.d/mysql.server start
4. 이제 모든 노드가 실행되었으니 MGM 노드 클라이언트를 띄워 간단히 테스트를 해보자.
Ndb_mgm명령어를 입력하였을 때 정상적으로 동작하는 모습은 다음과 같이 프롬프트가 떨어지는 모습이다.
# ndb_mgm -- NDB Cluster -- Management Client -- ndb_mgm>
5. 이제 show명령어를 사용하여 클러스터의 모든 노드들이 정상적으로 연동되는지 확인을 해 보자. HELP 를 입력하면 다른 명령어들도 확인해 볼 수 있다. 다음과 같이 4개의 노드를 구성하는 것에 성공하였다.
ndb_mgm> show Connected to Management Server at: 192.168.0.10:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.0.30 (Version: 4.1.13, Nodegroup: 0, Master) id=3 @192.168.0.40 (Version: 4.1.13, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.0.10 (Version: 4.1.13) [mysqld(API)] 1 node(s) id=4 (Version: 4.1.13) ndb_mgm>
MySQL 클러스터의 제한
MySQL Cluster 4.1.x 버전은 다음과 같은 사용상의 제한점을 지닌다.
- 트랙잭션 수행 중의 롤백을 지원하지 않으므로, 작업 수행 중에 문제가 발생하였다면, 전체 트랙잭션 이전으로 롤백하여야 한다.
- 실제 논리적인 메모리의 한계는 없으므로 물리적으로 허용하는 만큼 메모리를 설정하는 것이 가능하다.
- 컬럼 명의 길이는 31자, 데이터베이스와 테이블 명은 122자까지 길이가 제한된다. 데이터베이스 테이블, 시스템 테이블, BLOB인덱스를 포함한 메타 데이터(속성정보)는 1600개까지만 가능하다.
- 클러스터에서 생성할 수 있는 테이블 수는 최대 128개이다.
- 하나의 로우 전체 크기가 8KB가 최대이다(BLOB를 포함하지 않은 경우).
- 테이블의 Key는 32개가 최대이다.
- 모든 클러스터의 기종은 동일해야 한다. 기종에 따른 비트저장방식이 다른 경우에 문제가 발생하기 때문이다.
- 운영 중 스키마 변경이 불가능하다.
- 운영 중 노드를 추가하거나 삭제할 수 없다.
- 최대 데이터 노드의 수는 48개이다.
- 모든 노드는 63개가 최대이다. (SQL node, Data node, 매니저를 포함)
MySQL Cluster FAQ
Cluster 와 Replication의 차이
리플리케이션은 비동기화 방식이고, 클러스터는 동기화 방식이다. 따라서 리플리케이션은 일방적으로 데이타를 전달하여 복제를 하지만 클러스터는 동기방식이므로 데이타를 복제한 후 결과를 확인하기 때문에 데이타 누락이 발생하지 않는다. 다만 복제한 결과를 확인해야 하기 때문에 Cluster가 Replication보다는 속도가 느리다. 또한 Replication의 경우 복제된 데이터에 대한 신뢰를 할 수 없다.
Cluster가 사용하는 네트워크 (How do computers in a cluster communicate?)
MySQL 클러스터는 TCP/IP를 통해 서로 통신한다. 최소한 100Mbps의 이더넷을 사용해야 하며 원활한 통신을 위해 gigabit 이더넷을 권고한다. 실제 데이터가 메모리에 존재하여 사용되며 물리적인 측면에서 봤을 때 CPU, 메모리, 각 노드간의 통신을 위한 네트워킹이 주를 이룬다. 이중 가장 속도가 느린 네트워크의 속도를 높임으로써 전체적인 빠른 동작이 가능하도록 해야 한다. 또한, 더욱 빠른 SCI 프로토콜도 지원하며, 이는 특정 하드웨어를 필요로 한다.
클러스터를 구성하기 위해 컴퓨터가 얼마나 필요한가?
최소한 3대가 있어야 클러스터 구성이 가능하나, MGM 노드와 SQL 노드, 스토리지 노드 둘, 이렇게 4 대로 구성하길 권한다. 하나의 노드가 실패했을 때 지속적인 서비스를 하기 위해서 MGM노드는 분리된 컴퓨터에서 실행되어야 한다.
클러스터에서 각 컴퓨터들이 하는 일은?
MySQL 클러스터는 물리적, 논리적으로 구성된다. 컴퓨터는 물리적 요소이며 호스트라고 불리기도 한다. 논리적, 기능적 요소는 노드이다. 노드는 역할에 따라 MGM 노드, data 노드(ndbd), SQL 노드로 나뉜다.
MySQL 클러스터가 요구하는 하드웨어 사양은?
NDB가 설치되고 실행되는 모든 플랫폼이면 가능하나, 당연히 빠른 CPU, 높은 메모리에서 더 성능이 좋다(64-bit CPU에서 더 빠르다). 네트워크은 일반 TCP/IP를 지원하면 되고, SCI 를 지원하려면 특정 하드웨어가 요구된다.
MySQL 클러스터가 TCP/IP를 이용한다면 하나 이상의 노드를 인터넷을 통해 다른 곳에서 실행시킬 수 있는가?
가능하다. 하지만 MySQL 클러스터는 어떠한 보안도 제공되지 않으므로, 외부에서 클러스터 데이터 노드나 매니저 노드에 직접 접근하지 못하도록 해야 한다.
클러스터 사용을 위해 새로운 프로그래밍 언어나 쿼리를 배워야 하나?
표준 (My)SQL 쿼리나 명령을 사용하므로 그러지 않아도 된다.
클러스터 사용 시 에러나 경고 메시지는 어디서 찾나 ?
두 가지 방법이 있다. MySQL창에서 SHOW ERRORS나 SHOW WARNINGS로 확인하는 방법과 프롬프트 상태에서 perror --ndb error-code 를 사용하는 방법이 있다.
MySQL Cluster transaction-safe? 어떤 테이블 타입이 클러스터를 지원하나?
MySQL에서 NDB 스토리지 엔진과 생성된 테이블은 트랜잭션을 지원한다. NDB는 클러스터링만 지원하는 MySQL 스토리지 엔진이다.
"NDB" 의 의미는?
"Network Database".
클러스터를 지원하는 MySQL 버전은? 소스를 컴파일 해야 하나?
MySQL-max 4.1.3부터 지원한다. 바이너리 파일은 컴파일을 할 필요가 없다.
RAM은 얼마나 필요한가? 디스크는 사용하지 못하나?
클러스터는 오직 in-memory이며, 모든 테이블 데이터(인덱스 포함)가 RAM에 저장된다. 클러스터에서 필요한 RAM용량은 다음 공식으로 계산한다. (SizeofDatabase * NumberOfReplicas * 1.1 ) / NumberOfDataNodes
ERROR 1114: The table 'my_cluster_table' is full
위와 같은 에러가 발생했을 때는 할당된 메모리가 부족한 경우이다.
FULL TEXT 인덱스를 지원하는가?
현재 지원하지 않는다.
하나의 컴퓨터에서 여러 개의 노드가 돌아가는가?
가능하긴 하지만 권하진 않는다. 각 노드들이 다른 컴퓨터에서 실행되는 것이 더 안정적이다.
클러스터를 재시작하지 않고 노드를 추가할 수 있는가?
할 수 없다. MGM 이나 SQL 노드를 추가하려면 새로 시작해야 한다.
어떻게 기존의 MySQL 데이터베이스를 클러스터로 임포트 하는가?
ENGINE=NDB 나 ENGINE=NDBCLUSTER 옵션을 가진 테이블은 임포트할 수 있다. 또는 ALTER 기능으로 기존의 테이블을 클러스터로 변환 사용할 수 있다.
- ALTER TABLE OLD_TABLE ENGINE=NDBCLUSTER;
Arbitrator란 ?
클러스터에서 한 개 혹은 그 이상의 노드가 실패할 경우, MGM 서버나 다른 노드가 그 노드의 역할을 대신하여 다른 노드들로 하여금 실패한 노드와 같은 노드로 인식하게 하는 기능을 한다. 이런한 역할을 하는 노드를 중재인이라고 한다.
클러스터 shut down시에 어떤 일이 일어나는가?
클러스터 데이터 노드의 메모리에 있던 데이터가 디스크에 쓰여지고, 그 다음에 클러스터가 시작될 때 다시 메모리에 로드된다.
클러스터에서 다른 매니저 노드를 구성하는 것은?
fail-safe에 있어서 도움이 된다. 단지 하나의 MGM 노드 만이 클러스터를 컨트롤 할 수 있지만 MGM 노드 하나를 primary로, 추가의 매니저 노드를 primary MGM 노드가 실패했을 때 인계받도록 하면 된다.
5. MySQL Cluster Glossary
Cluster
일반적으로 Cluster는 하나의 업무를 수행하기 위해 함께 동작하는 컴퓨터 세트이다. NDB Cluster는 자료저장, 복구, 컴퓨터 간의 분배 관리 등을 시행하기 위해 MySQL을 사용하는 Storge Engine 이다. MySQL Cluster는 in-memory storage를 사용한 shared-noting 아키텍쳐에서 분산된MySQL DB를 지원하기 위해 NDB엔진을 사용하여 함께 돌아가는 컴퓨터 그룹이다.
Configuration Files
클러스터, 호스트, 노드에 관계된 직접적인 정보를 포함하는 파일이다. 클러스터 시작 시 Cluster의 MGM 노드가 읽어들인다.
Backup
디스크나 다른 Long-term Storage에 저장되는 모든 클러스터 데이타, 트랜젝션, 로그의 완전한 카피를 말한다.
Restore
백업에 저장되는 것과 같이 클러스터에 그 전 상태로 되돌리는 것을 말한다.
CheckPoint
일반적으로 데이타가 디스크에 저장될 때 체크포인트에 도달한다고 말한다. 클러스터에서는 Committed된 트랜잭션을 디스크에 저장하는 시간을 말한다. NDB Storage Engine에는 일관되게 클러스터의 데이타를 보존하기 위해 두 종류의 CheckPoint가 있다. LocalCheckPoint(LCP) : 싱글 노드의 체크포인트. 그러나 클러스터의 모든 노드에서 LCP를 사용한다. LCP는 디스크에 노드의 모든 데이타를 저장하도록 한다(보통 매 몇 분마다). 클러스터 Activity의 노드와 레벨, 다른 요인에 의해 저장되는 데이타의 양은 의존적이다. GlobalCheckPoint(GCP) : GCP는 모든 노드의 트랜잭션이 동기화되고, redo-log가 Disk에 저장될 때 몇 분마다 발생한다.
Cluster Host
MySQL Cluster의 구성 컴퓨터. 클러스터는 물리적 구조와 논리적 구조를 가진다. 물리적으로 클러스터는 Cluster Host라는 컴퓨터의 수로 구성된다.
Node
MySQL Cluster의 논리적, 기능적 요소를 말하며 Cluster Node라고도 한다. MySQL Cluster에서는 node란 용어를 Cluster의 물리적 Component인 Process를 지칭한다. MySQL Cluster가 동작하기 위해 3가지 타입의 노드가 있다.
MGM node - MySQL Cluster에서 다른 노드들의 설정 정보, 노드의 시작과 정지, 네트워크 파티셔닝, 백업과 저장 등을 포함하여 다른 노드들을 관리한다.
SQL node (MySQL Server) - 클러스터의 데이터 노드안에 저장된 데이터를 Serve 하는 MySQL Server 인스턴스. 데이타를 저장, 분배, 업데이트하는 클라이언트는 MySQL Server를 통해 접근 가능하다.
Data node - 이 노드는 실제 데이타를 저장한다. 현재 싱글 클러스터는 총 48개의 데이타 노드를 지원한다.
싱글 머신에 한 개 이상의 노드가 공존할 수도 있고, 한 머신에 완전한 클러스터를 구성하는 것도 가능하다. MySQL 클러스터에서 호스트는 클러스터의 물리적 컴퍼넌트이며, 노드는 논리적 혹은 기능적인 컴퍼넌트, 즉 프로세스라는 것을 잊지 말자.
Node group
데이터 노드의 집합. 노드 그룹 안의 모든 데이터 노드는 같은 데이터(fragment)를 포함한다. 그리고 싱글 그룹의 모든 노드는 다른 호스트에 존재해야 한다.
Node failure
MySQL 클러스터는 클러스터를 구성하는 어느 한 노드의 기능에만 의존적이지 않다. 클러스터는 하나 혹은 몇 개의 노드가 실패해도 계속될 수 있다.
Node restart
실패한 클러스터 노드의 리스타팅 과정.
Initial node restart
노드의 이전의 파일 시스템을 지우고 시작하는 클러스터 노드의 과정. 소프트웨어 향상과 그 밖의 특별한 상황 등에 사용된다.
System crash(or System fail)
클러스터의 상태가 확인되지 않는 등 많은 클러스터 노드가 실패했을 때 일어날 수 있다.
System restart
클러스터의 리스타팅과 디스크 로그 및 체크 포인트로부터 reinstall하는 프로세스를 말한다. 클러스터를 shutdown 한 이후에 일어나는 과정이다.
fragment
데이터베이스 테이블의 한 부분. NDB스토리지 엔진에서 테이블을 나누어 fragments의 수에 따라 저장한다. Fragment는 파티션이라 불리기도 한다. MySQL 클러스터에서 테이블은, 머신과 노드 간의 로드 밸런싱을 용이하게 할 수 있도록 fragment된다.
Replica
NBD 스토리지 엔진에서 각 테이블 프레그먼트는 여분을 포함하여 다른 데이터 노드에 저장된 많은 replica를 갖는다. 현재는 fragment 당 4개 이상의 replica가 가능하다.
Transpoter
노드들 간의 데이터 이동을 제공하는 프로토콜 TCP/IP(local), TCP/IP(remote), SCI, SHM(MySQL 4.1 버전에서 실험적임)
NDB(Network DataBase)
NDB는 MySQL클러스터에서 사용하는 스토리지 엔진을 말 함. NDB 스토리지 엔진은 모든 일반적인 MySQL 컬럼 타입과 SQL문을 지원하며, ACID(DB무결성 보장을 위한 트랜잭션)성질을 가진다.
Shared-nothing architecture
MySQL 클러스터의 이상적인 아키텍쳐. 진정한 Shared-nothing setup 에서 각 노드는 분리된 호스트에서 실행된다. 이러한 배열은 싱글 호스트나 싱글 노드가 아니면 SOF나 시스템 병목현상이 전체적으로 발생할 수 있다는 데 있다.
In-memory storage
각 데이터 노드에 저장된 모든 데이터는 그 노드의 호스트 컴퓨터의 메모리에 유지된다. 클러스터의 각 데이터 노드를 위해, (데이터 노드의 수로 나뉜 replica의 수 * 데이터베이스 사이즈)만큼의 가용 RAM의 양을 확보해 두어야 한다. 그러니까, 데이터베이스가 1기가의 메모리를 차지하고, 4개의 replica와 8개의 노드로 클러스터를 구성하고자 하면, 각 노드당 최소 500MB의 메모리가 필요하다. 그리고 OS와 다른 어플리케이션 프로그램이 쓰는 메모리가 추가로 필요하다.
Table
관계형 데이터베이스에서는 table은 일반적으로 동일하게 구조화된 레코드의 set을 가리킨다. MySQL 클러스터에서 데이터베이스 테이블은 fragment의 set으로써 데이터 노드에 저장되고, 각 fragment는 추가로 데이터 노드에 복제된다. 같은 fragment를 replicate한 데이터 노드의 set이나 fragment의 set을 노드 그룹이라 한다.
Cluster Programs : 명령어들
서버 데몬
- ndbd : 데이터 노드 데몬
- ndb_mgmd : MGM서버 데몬
- ndb_mgm : MGM 클라이언트
- ndb_waiter : 클러스터의 모든 노드들의 상태를 확인할 때 사용
- ndb_restore : 백업으로부터 클러스터의 데이터를 복구할 때 사용
Dual-Master Replication in MySQL
송은영 (f405@sds.co.kr), 김홍섭(hskim@sds.co.kr), 방창현(winchild@sds.co.kr)-등록및포매팅 / (주)삼정데이터서비스 연구소
최종수정일: 2006년1월2일 01시35분
![[-]](http://wiki.kldp.org/imgs/plugin/arrup.png "[-]")
1.1 Replication 이란?
1.2.1 MASTER 와 SLAVE 설치
1.2.2 MASTER 계정생성
slave 서버에서 master 서버에 접속할 수 있도록, master 서버에 계정을 만든다. 사용자를 추가해 주어야 한다는 말이다. 이 계정에 REPLICATION SLAVE 권한을 주어야 한다. replication에만 사용할 계정이라면 추가적인 권한은 주지 않아도 된다. slave 서버에서master 서버에 접속할 계정과 패스워드에 권한을 부여하는 명령은 다음과 같다.
master mysql > GRANT REPLICATION SLAVE ON *.*
-> TO 'user_name'@'user_host' IDENTIFIED BY 'user_password';
여기서 user_name은 중복되지 않는 이름이면 되며, user_host 는 slave로 만들 서버의 주소 혹은 도메인 네임을 적어준다. 이 주소의 slave 유저만 master 서버로 접속할 수 있다. 4.0.2 이전 버전의 MySQL에서는, REPLICATION SLAVE 권한이 없으므로, 다음과 같이 FILE 권한으로 대신한다.
master mysql > GRANT FILE ON *.*
-> TO 'user_name'@'user_host' IDENTIFIED BY 'user_password';
1.2.3 MASTER 데이터 SLAVE 에 복사
master 서버의 기본 데이터를 백업 받아, slave 서버의 데이터베이스에 복사한 후, 데이터 디렉토리에서 압축을 푼다.
HOT 백업
master mysql > FLUSH TABLES WITH READ LOCK; master shell > tar -cvf /tmp/mysql-snapshot.tar . slave shell > tar -xvf /tmp/mysql-snapshot.tar master mysql > UNLOCK TABLES;
mysqldump 이용 백업
master Shell > mysqldump -u root -p ‘password’ -B db_name > dump_file.sql
1.2.4 MASTER 환경설정
Master 와 Slave 의 데이터 베이스 환경을 설정한다. 우선 master 서버를 설정하도록 한다.
master shell> vi /etc/my.cnf
master 서버는 디폴트로 구성이 되어 있을 것이므로, mysqld 섹션에 log-bin이 있는 지 확인한다.
[mysqld] log-bin server-id = 1
1.2.5 SLAVE 환경설정
다음은 slave 서버의 환경설정이다.
slave shell> vi /etc/my.cnf
mysqld 섹션으로 가서 server-id를 master 서버의 server-id와 다르게 설정한다. 본 문서에서는 2로 설정하도록 하겠다. slave 서버를 여러 대로 구축하고자 할 때에 각 slave 서버의 server-id는 각각 달라야 한다는 것에 주의하자. 2^32-1까지 가능하다.
[mysqld] server-id = 2 master-host = xxx.xxx.xxx.xxx(user_host) master-port = 3306 master-user = user_name master-password = user_password
master 서버의 데이터를 백업 받았다면, slave 서버를 시작하기 전에 slave 서버의 데이터 디렉토리에 master 서버의 데이터를 복사해 둔다. mysqldump를 사용했다면, 다음으로 가서 먼저, slave 서버를 스타트한다.
1.2.7 SLAVE 덤프파일 LOAD
mysqldump를 사용해 백업 파일을 만들었다면, slave 서버에 덤프 파일을 로드시킨다.
slave shell > mysql -u root -p < dump_file.sql
1.2.8 MASTER 계정 설정
slave 서버에서 master-host, master-user, master-password 등의 설정을 다음과 같이 바꿀 수도 있다. 물론 /etc/my.cnf에서 설정하지 않았을 경우에도 쓸 수 있다.
slave mysql > CHANGE MASTER TO
-> MASTER_HOST='master_host_name',
-> MASTER_USER='replication_user_name',
-> MASTER_PASSWORD='replication_password',
-> MASTER_LOG_FILE='recorded_log_file_name',
-> MASTER_LOG_POS=recorded_log_position;
각 옵션의 최대 길이는 다음과 같다.
MASTER_HOST 60 MASTER_USER 16 MASTER_PASSWORD 32 MASTER_LOG_FILE 255
1.2.10 SUCCESS CERTIFICATION
mysql/data/slave.err을 확인하여 다음과 같은 메시지가 있으면 성공적으로 설정된 것이다.
Slave I/O thread: connected to master 'user_name@user_host:3306', replication started in log 'FIRST' at position 4
1.3 How to Set Up Dual-Master Replication
우선 이후에서는 지금까지 master 라고 칭했던 서버를 mysql1 서버라고 하고, slave라 칭했던 서버를 mysql2 서버라 하겠다. 듀얼 마스터 리플리케이션을 구축할 두 대의 서버에는 동일 버전의 최신 MySQL이 설치되어 있으며, Master-Slave 리플리케이션이 구축된 상태에 있다고 간주한다.
이미 앞에서 리플리케이션 구축에 대해 자세히 설명하였으므로, 과정에 대해서만 기술하기로 하겠다.
1.3.4 GRANT REPLICATION SLAVE
d. mysql2 서버에서 GRANT REPLICATION SLAVE명령을 실행한다. Dual-Master란 것이 서로가 서로의 master이자 slave가 되는 것이므로, 이전의 설치에서 slave였던 mysql2가 mysql1 서버의 유저를 slave 유저로 갖게 된다.
mysql2 mysql > GRANT REPLICATION SLAVE ON *.*
-> TO 'users_name'@'users_host' IDENTIFIED BY 'users_password';
1.3.5 MASTER SETUP
이제 mysql1 서버로 이동하여, 설정을 계속한다. 우선, mysql1 서버의 mysql 구동을 멈춘다.
mysql1 shell > /etc/init.d/mysqld stop
1.3.6 MASTER CONFIGURATION
mysql1 서버의 /etc/my.cnf 파일을 수정한다. mysqld 섹션으로 가서 mysql2 서버를 마스터로 간주하도록 정보를 추가한다.
[mysqld] server-id = 1 <= 그대로 두고, 아래 내용을 추가한다. master-host = users_host master-port = 3306 master-user = users_name master-password = users_password
1.3.8 SUCCESS CERTIFICATION
mysql/data/mysql1.err을 확인하여 다음과 같은 메시지가 있으면 성공적으로 설정된 것이다.
Slave I/O thread: connected to master 'ccotti@222.112.137.172:3306', replication started in log 'FIRST' at position 4
지금까지 별다른 문제없이 설치를 진행하였다면, 각 서버의 mysql 모니터에서 데이터를 입력하고, 두 서버가 서로 연동이 되는 것을 확인할 수 있을 것이다.
1.4 장애복구
위의 설정에서 두 대의 서버 중 한 대가 장애를 일으키는 경우 한 서버를 리부팅한다고 가정할 때, 별도의 설정이 없다면 기존의 MySQL 리플리케이션 구성에서는 두 서버 간의 동기화가 원활히 일어나지 않았다. 그런 경우 다음을 순서대로 진행하며, 장애를 복구할 수 있다. 우선 mysql1 서버를 재시작해야 한다고 가정하자.
1. mysql1의 mysql/data/ 의 mysql1-bin.*를 지운다.
2. mysql1의 mysqld를 시작한다.
mysql1 shell > /etc/init.d/mysqld start
3. mysql2의 mysql 모니터에서 다음 명령어를 실행한다.
mysql2 mysql > slave stop; mysql2 mysql > slave reset; mysql2 mysql > slave start;
[edit]
1.5 참고
● master와 slave 데이터 일치 방법
- master mysql을 정지시키고 대상 파일들을 백업(복사) - master mysql을 구동
● slave에서 'LOAD TABLE FROM MASTER' 나 'LOAD DATA FROM MASTER' 명령을
-> 이 후 변경사항들이 bin-log에 기록됨
- slave에 백업한 DB 파일들을 복사 후 구동
-> master의 bin-log를 참고하여 데이터 일치됨 ※ 이 때, 복사한 파일의 소유자(mysql인지?) 확인 철저 ※ my.cnf 설정에서 특정 DB를 선택한 경우 master와 slave 모두 동일하게 설정해야 함
(한 쪽은 설정하지 않고 한 쪽은 설정한 경우 오동작)
※ my.cnf 주의사항 : mysql_safe 실행 시 DB_DIR 옵션에 따라 불러오는 위치 달라짐
사용하기 위해서는 replication 계정에 다음은 권한 추가 필요
- SUPER, RELOAD, SELECT 권한을 replication 계정에 부여 ● 다음 명령을 통해 mysql의 내부cache를 clear시키고 쓰기 방지 가능
※ mysql 기본 테이블인 MyISAM 테이블을 사용할 경우 - mysql> FLUSH TABLES WITH READ LOCK;
● 쓰기 방지 해제 명령
- mysql> UNLOCK TABLES;
● slave의 mysql을 replication 미적용하고 구동 방법
- /usr/local/bin/mysqld_safe --skip-slave-start ● slave 동작 구동 방법 - mysql> start slave;
● replication 정상동작 확인
※ slave 설정 미인식 등의 문제 발생 시
mysql> change master to 명령을 사용하여 설정
- mysql> show processlist;
또는 mysql> show processlist\G ; 상세한 내용 확인
- mysql> show slave status;
또는 mysql> show slave status\G ; 상세한 내용 확인 또는 mysql> show master status;
- error 로그 확인◆◆ 소개하기
SQL(Structured Query Language)의 가장 큰 특징 중의 하나는 여러개의 테이블을
연결시켜 데이터를 검색하거나 조작할 수 있는 기능이다. 이것은 데이터를 쉽고
빠르게 검색하고 불필요한 데이터를 줄여주는 장점이 있다. 다른 SQL 언어와 마찬
가지로 MySQL도 join명령어로 이 연산을 수행한다.
간단히 말하면 join은 두개 이상의 테이블로부터 필요한 데이터를 연결해 하나의
포괄적인 구조로 결합시키는 연산이다.
예를 들어, 한 컴퓨터 제조업자가 자신의 데이터를 능률적으로 관리하기 위한
데이터베이스가 필요하다고 하자. 이 데이터들은 주문, 고객, 생산과 같은 어떤
일관성있는 개념과 관련된 각각의 데이터들이 모여 다양하고 간결한 테이블들을
이룰 것이다. 테이블을 생성한 후에는, 다양한 예를 들어 데이터베이스에서 가장
많이 사용되는 join의 조작법에 대해 설명하겠다.
첫번째 테이블은 제조업자가 분류한 다양한 타입의 PC들의 데이터로 구성될 것이다.
----------------------------------------------
mysql> create table pcs (
-> pid INT, // product id
-> spec char(3),
-> os char(10),
-> ram INT,
-> hd char(4)
-> );
-----------------------------------------------
두번째 테이블은 제조업자의 다양한 고객들에 관한 데이터로 이루어질 것이다.
-----------------------------------------------
mysql> create table clients (
-> name char(25),
-> cid char(8), // client id
-> email char(25),
-> tel char(10)
-> );
-----------------------------------------------
세번째 테이블은 주문 정보에 관한 데이타를 포함할 것이다.
-----------------------------------------------
mysql> create table orders (
-> order_date date,
-> pid INT,
-> cid char(8)
-> );
-----------------------------------------------
◆◆ 자료(Data) 삽입하기
각각의 테이블에 아래와 같이 자료를 삽입해 보자.
☆ pcs (테이블1)
+------+------+-------+------+------+
| pid | spec | os | ram | hd |
+------+------+-------+------+------+
| 1 | 386 | Linux | 64 | 3.1 |
| 2 | 386 | Linux | 128 | 4.2 |
| 3 | 486 | WinNT | 64 | 3.1 |
| 4 | 586 | Linux | 128 | 4.2 |
| 5 | 586 | Win98 | 128 | 6.4 |
+------+------+-------+------+------+
[삽입방법]
-----------------------------------------------------------
mysql> INSERT INTO pcs (pid, spec, os, ram, hd)
-> VALUES (1, '386', 'Linux', 64, '3.1');
-----------------------------------------------------------
☆ clients (테이블2)
+--------+---------+---------------------------+------------+
| name | cid | email | tel |
+--------+---------+---------------------------+------------+
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 |
| 홍길동 | hgd-043 | honggd at won.hongik.ac.kr | 421-555-34 |
| 이쁘니 | pty-042 | pretty at won.hongik.ac.kr | 459-555-32 |
| 못난이 | ugy-043 | ugly at won.hongik.ac.kr | 439-555-88 |
+--------+---------+---------------------------+------------+
[삽입방법]
-----------------------------------------------------------
mysql> INSERT INTO clients (name, cid, email, tel)
-> VALUES ('원주희', 'wjh-042',
-> 'haremoon at won.hongik.ac.kr', '123-456-7890');
-----------------------------------------------------------
☆ orders (테이블3)
+------------+------+---------+
| order_date | pid | cid |
+------------+------+---------+
| 1999-12-05 | 2 | wjh-042 |
| 1999-12-04 | 3 | hgd-043 |
| 1999-12-04 | 1 | wjh-042 |
| 1999-12-05 | 2 | wjh-042 |
| 1999-12-12 | 5 | ugy-043 |
| 1999-12-05 | 5 | pty-042 |
+------------+------+---------+
[삽입방법]
-----------------------------------------------------------
mysql> INSERT INTO orders (order_date, pid, cid)
-> VALUES ('1999-12-05', 2, 'wjh-042');
-----------------------------------------------------------
자, 이제부터 만들어진 3개의 테이블로부터 필요한 데이터만을 추출해 결합하는
방법에 대해 알아보자. 만일 당신의 상사가 특정한 날에 특정한 PC를 주문한 모든
고객의 이메일 목록을 원한다고 하자! 또는 특정한 고객에 의해 작성된 주문서에
있는 RAM의 양을 보고받기를 원한다고 하자. 이러한 모든 일들은 다양한 join문에
의해 쉽게 수행될 수 있다. 만들어진 테이블을 사용해 첫번째 join문을 생성해보고
작성해보자.
◆◆ The Cross Join
Cross Join은 가장 기본적인 join의 타입으로 한 테이블에 있는 각각의 열이 다른
테이블의 모든 열에 간단하게 매치되어 출력된다. 능률적이지는 않지만, 모든 join
의 공통된 특징을 나타내준다.
Cross Join의 간단한 예 :
----------------------------------------------
mysql> SELECT * FROM pcs, clients;
----------------------------------------------
매우 많은 열들이 출력될 것이다. 테이블1(pcs)에 있는 각각의 열이
테이블2(clients)
의 모든 열에 매치된다는 것을 기억하자. 따라서, 3 열을 가진 테이블1(pcs)과 4
열을
가진 테이블2(clients)를 포함한 join문은 총 12 열의 테이블을 만들것이다.
즉 cross-join은 테이블1에 있는 각각의 열들이 테이블2에 있는 모든열들을 한 번씩
교차해 출력한다고 기억하는 것이 쉬울 것같다.
첫번째 join을 성공적으로 수행했다면 다음의 예도 어렵지 않을 것이다.
아래의 예를 따라해 보고 어떤 결과가 출력될지 예상해보자.
-----------------------------------------------------------------------------
mysql> select c.name, o.cid from orders o, clients c where o.cid = "wjh-042";
-----------------------------------------------------------------------------
+--------+---------+
| name | cid |
+--------+---------+
| 원주희 | wjh-042 |
| 원주희 | wjh-042 |
| 원주희 | wjh-042 |
| 홍길동 | wjh-042 |
| 홍길동 | wjh-042 |
| 홍길동 | wjh-042 |
| 이쁘니 | wjh-042 |
| 이쁘니 | wjh-042 |
| 이쁘니 | wjh-042 |
| 못난이 | wjh-042 |
| 못난이 | wjh-042 |
| 못난이 | wjh-042 |
+--------+---------+
예상한 대로 결과가 출력되었나? clients 테이블에 있는 각각의 name이 orders테이
블의 "wjh-042"를 포함한 열마다 매치되어 출력되었다. 지금까지의 설명이 Cross
Join을 설명하는데 충분하지 않으므로 다른 질의를 사용해가며 JOIN을 활용해보기
바란다.
NOTE : 왜 테이블의 이름에 별명을 주어 사용할까? Aliases(별명)은 질의를 입력할
때 반복적인 키의 입력을 줄여주는 방법으로 사용되어진다. 따라서 열을 지정해 줄
때 반복적으로 'clients'를 한자 한자 입력하는 대신에, 질의내에 'from clients c'
를 지정해주고 'c'를 사용할 수 있다.
Cross Join이 테이블들을 연결해 주기는 하지만, 능률적이지는 못하다. 따라서
각각의 테이블들로 부터 우리가 원하는 데이타를 어떻게 하면 쉽게 선택할 수 있는지
계속 다음 장을 읽어보기 바란다.
◆◆ The Equi-join
Equi-join은 한 테이블에 있는 어떠한 값이 두번째(또는 다수의) 테이블내에 포함된
값에 일치 할 때 수행된다.
product id 가 1인 PC를 주문한 고객의 목록을 원한다고 가정해 보자.
-------------------------------------------------------------------
mysql> select p.os, c.name from orders o, pcs p, clients c
-> where p.pid=o.pid and o.pid = 1 and o.cid=c.cid;
-------------------------------------------------------------------
+-------+--------+
| os | name |
+-------+--------+
| Linux | 원주희 |
+-------+--------+
◆ Non-Equi-join
Equi-join은 다수의 테이블들 사이에서 일치하는 자료들만을 추출해낸다. 그러나
만일 일치하지 않은 자료들만을 추출해야 한다면...? 예를 들어, 당신의 상사가
주문한 pid가 제품의 pid보다 더 큰 order id의 모든 운영체제(OS)의 목록을
필요로 한다면 어떻게 할 것인가? 적당히 이름을 non-equi join라고 하겠다.
-------------------------------------------------------------------
mysql> SELECT p.os, o.pid from orders o, pcs p where o.pid > p.pid;
-------------------------------------------------------------------
+-------+------+
| os | pid |
+-------+------+
| Linux | 2 |
| Linux | 3 |
| Linux | 2 |
| Linux | 5 |
| Linux | 5 |
| Linux | 3 |
| Linux | 5 |
| Linux | 5 |
| WinNT | 5 |
| WinNT | 5 |
| Linux | 5 |
| Linux | 5 |
+-------+------+
orders 테이블의 pid가 pcs테이블의 pid보다 더 큰 모든 열들이 매치될 것이다.
주의깊게 살펴보면, 여러가지 제한을 준 간단한 cross-join 임을 파악할 수 있
을 것이다. 상사에게는 특별하게 유용하지 않을 지도 모르지만, 매우 유용한 기
능인 left join을 위한 준비 과정으로 생각하자. 자, 이제 다음장으로 가서
left join을 사용할 때 유용할 수있는 옵션들에 대해 집중적으로 알아보자.
◆◆ The Left Join
Left Join은 사용자가 어떠한 제한을 기반으로 관심있는 모든 종류의 자료를 추출
하게한다. 테이블 join중 가장 막강한 옵션으로, 테이블을 매우 쉽게 조작할 수
있게 한다.
만일 상사가 좀더 자세히, 자세히, 자세하게, 자세하게!를 외친다고 가정해보자.
left join이 우리의 문제를 해결해 줄 것이다.
-------------------------------------------------------------------
mysql> select * from orders left join pcs on orders.pid = pcs.pid;
-------------------------------------------------------------------
+------------+------+---------+------+------+-------+------+------+
| order_date | pid | cid | pid | spec | os | ram | hd |
+------------+------+---------+------+------+-------+------+------+
| 1999-12-05 | 2 | wjh-042 | 2 | 386 | Linux | 128 | 4.2 |
| 1999-12-04 | 3 | hgd-043 | 3 | 486 | WinNT | 64 | 3.1 |
| 1999-12-04 | 1 | wjh-042 | 1 | 386 | Linux | 64 | 3.1 |
| 1999-12-05 | 2 | wjh-042 | 2 | 386 | Linux | 128 | 4.2 |
| 1999-12-12 | 5 | ugy-043 | 5 | 586 | Win98 | 128 | 6.4 |
| 1999-12-05 | 5 | pty-042 | 5 | 586 | Win98 | 128 | 6.4 |
+------------+------+---------+------+------+-------+------+------+
고객이 주문한 모든 PC들의 목록을 추출해 낸다. 예를 들어, PHP3 또는 Perl
스크립트를 사용해 영수증을 출력하는데 사용할 수도 있다. 고객들에게 우리회
사로부터 구입한 모든 제품의 목록을 가끔씩 메일로 보내야 할 때에도
clients 테이블과 연결해 사용할 수 있을 것이다.
아래의 예에서 우리는 제품의 id(pid)가 3인 PC의 정보만을 볼 수 있다.
-------------------------------------------------------------------
mysql> select * from orders left join pcs on pcs.pid=3 and pcs.pid=orders.pid;
-------------------------------------------------------------------
+------------+------+---------+------+------+-------+------+------+
| order_date | pid | cid | pid | spec | os | ram | hd |
+------------+------+---------+------+------+-------+------+------+
| 1999-12-05 | 2 | wjh-042 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-04 | 3 | hgd-043 | 3 | 486 | WinNT | 64 | 3.1 |
| 1999-12-04 | 1 | wjh-042 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-05 | 2 | wjh-042 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-12 | 5 | ugy-043 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-05 | 5 | pty-042 | NULL | NULL | NULL | NULL | NULL |
+------------+------+---------+------+------+-------+------+------+
◆ The Using Clause
left join에 약간의 옵션을 주어 둘 이상의 테이블에 있는 동일한 컬럼을 조금 더
깊게 연관지을수도 있다. on과 using옵션이 사용되며, 아래의 예제를 참조하자.
--------------------------------------------------------------------
## 원본의 예제는 아래와 같지만, 에러가 발생해 필자가 MySQL매뉴얼을 참조해
나름대로 수정을 했다.##
mysql> SELECT * from clients join on orders where clients.cid = orders.cid;
mysql> SELECT * from clients join on orders using (cid);
-------------------------------------------------------------------
==> 수정한 예제
-------------------------------------------------------------------
mysql> SELECT * from clients left join orders on clients.cid = orders.cid;
-------------------------------------------------------------------
또는 아래와 같이 나타낼 수도 있다.
-------------------------------------------------------------------
mysql> SELECT * from clients left join orders using (cid);
-------------------------------------------------------------------
두 예제 모두 똑같은 결과가 출력될 것이다.
+--------+---------+---------------------------+------------+------------+------+---------+
| name | cid | email | tel | order_date | pid |
cid |
+--------+---------+---------------------------+------------+------------+------+---------+
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 | 1999-12-05 | 2 |
wjh-042 |
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 | 1999-12-04 | 1
| wjh-042 |
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 | 1999-12-05 | 2
| wjh-042 |
| 홍길동 | hgd-043 | honggd at won.hongik.ac.kr | 421-555-34 | 1999-12-04 | 3
| hgd-043 |
| 이쁘니 | pty-042 | pretty at won.hongik.ac.kr | 459-555-32 | 1999-12-05 | 5
| pty-042 |
| 못난이 | ugy-043 | ugly at won.hongik.ac.kr | 439-555-88 | 1999-12-12 | 5
| ugy-043 |
+--------+---------+---------------------------+------------+------------+------+---------+
다른 구문의 예를 적용해 가며 left join에 대해 이해하기 바란다. 공부를 하다보면
left join이 여러분의 개발활동에 매우 중요한 역할을 한 다는 것을 느낄 것이다.
테이블 join에 관한 정보를 좀더 깊게 교환하고 싶다면 http://www.mysql.com에 있는
다양한 토론 그룹을 체크해 보기 바란다.
◆◆ Self-joins
Self-join은 관리자가 하나의 테이블에 관련된 데이타를 집중시키는 막강한 방법을
제공해 준다. 사실, self-join은 그 자신의 테이블에 결합하는 것에 의해 수행된다.
개념의 이해를 위해 예를 들어 설명하겠다.
컴퓨터 워크스테이션을 만드는데 사용되는 하드웨어의 다양한 부품에 관한 정보를
가진 매우 큰 데이타베이스를 관리해야 한다고 가정하자. 워크스테이션은 데스크,
PC, 모니터, 키보드, 마우스등으로 이루어져 있다. 게다가, 데스크는 워크스테이션의
모두 다른 부분의 '부모'라고 생각될 수 있다. 우리는 각 워크스테이션의 레코드가
정확한 자료로 유지되기를 원할 것이며, 유일한 ID번호를 부여함으로써 워크스테이션
의 모든 부분을 구체적으로 관련시킬 것이다. 사실, 각 부분은 항목을 분명하게
해주는
유일한 ID번호와 그것의 부모(데스크) ID번호를 확인하기 위한, 두개의 ID 번호를
포함 것이다.
테이블이 아래와 같다고 가정하자.
mysql> select * from ws;
+---------+-----------+-----------+
| uniq_id | name | parent_id |
+---------+-----------+-----------+
| d001 | desktop | NULL |
| m4gg | monitor | d001 |
| k235 | keyboar | d001 |
| pc345 | 200mhz pc | d001 |
| d002 | desktop | NULL |
| m156 | monitor | d002 |
| k9334 | keyboar | d002 |
| pa556 | 350mhz pc | d002 |
+---------+-----------+-----------+
desktop은 그와 관련된 모든 부분들의 부모와 같으므로 parent_id를 가지고 있지
않음을 주목하자. 지금부터 유용한 정보를 위한 질의를 시작할 것이다. self-join
의 사용법을 쉽게 설명하기 위해 테이블을 간단하게 만들었다.
-------------------------------------------------------------------
mysql> select t1.*, t2.* from ws as t1, ws as t2;
-------------------------------------------------------------------
어떻게 출력되는가? 이전처럼, 첫번째 테이블의 각 열들이 두번째 테이블에 있는
모든 열들에 매치되어 연결되 출력될 것이다. 우리에게 매우 유용하지는 않지만
다시 한번 시도해보고 확인해 보기바란다. 좀더 재미있는 예를 들어보겠다.
-------------------------------------------------------------------
mysql> select parent.uniq_id, parent.name, child.uniq_id, child.name
-> from ws as parent, ws as child
-> where child.parent_id = parent.uniq_id and parent.uniq_id = "d001";
-------------------------------------------------------------------
흥미로운 결과가 출력될 것이다.
+---------+---------+---------+-----------+
| uniq_id | name | uniq_id | name |
+---------+---------+---------+-----------+
| d001 | desktop | m4gg | monitor |
| d001 | desktop | k235 | keyboar |
| d001 | desktop | pc345 | 200mhz pc |
+---------+---------+---------+-----------+
self-join은 테이블의 자료를 검증하는 방법으로도 사용된다. 테이블내에 있는
uniq_id컬럼은 테이블에서 유일해야 하며, 만일 데이타의 엔트리가 깊어 뜻하지
않게 같은 uniq_id를 가진 두개의 항목이 데이타베이스에 입력된다면 좋지 않은
결과가 생길것이다. 이럴 경우 정기적으로 self-join을 사용해 체크할 수 있다.
우리는 350mhz pc의 uniq_id가 'm156'(이 값은 워크스테이션 'd002'에 속한
모니터의 uniq_id 값이다.)이 되도록 변경했다고 가정하자.
테이블의 내용은 다음과 같이 변경한다.
-------------------------------------------------------------------
mysql> update ws set uniq_id = 'm156' where name = '350mhz pc';
-------------------------------------------------------------------
아래의 예를 참고해 ws테이블에 self-join을 적용해보자.
-------------------------------------------------------------------
mysql> select parent.uniq_id, parent.name, child.uniq_id, child.name
-> from ws as parent, ws as child
-> where parent.uniq_id = child.uniq_id and parent.name <> child.name;
-------------------------------------------------------------------
아래와 같이 출력될 것이다.
+---------+-----------+---------+-----------+
| uniq_id | name | uniq_id | name |
+---------+-----------+---------+-----------+
| m156 | 350mhz pc | m156 | monitor |
| m156 | monitor | m156 | 350mhz pc |
+---------+-----------+---------+-----------+
Table join은 데이터베이의 관리를 쉽게 도와줄것이다. 구문의 이해를 정확하게
하기위해서 예제에서 배운 명령을 다양하게 변화시켜 적용해보기 바란다.
SQL(Structured Query Language)의 가장 큰 특징 중의 하나는 여러개의 테이블을
연결시켜 데이터를 검색하거나 조작할 수 있는 기능이다. 이것은 데이터를 쉽고
빠르게 검색하고 불필요한 데이터를 줄여주는 장점이 있다. 다른 SQL 언어와 마찬
가지로 MySQL도 join명령어로 이 연산을 수행한다.
간단히 말하면 join은 두개 이상의 테이블로부터 필요한 데이터를 연결해 하나의
포괄적인 구조로 결합시키는 연산이다.
예를 들어, 한 컴퓨터 제조업자가 자신의 데이터를 능률적으로 관리하기 위한
데이터베이스가 필요하다고 하자. 이 데이터들은 주문, 고객, 생산과 같은 어떤
일관성있는 개념과 관련된 각각의 데이터들이 모여 다양하고 간결한 테이블들을
이룰 것이다. 테이블을 생성한 후에는, 다양한 예를 들어 데이터베이스에서 가장
많이 사용되는 join의 조작법에 대해 설명하겠다.
첫번째 테이블은 제조업자가 분류한 다양한 타입의 PC들의 데이터로 구성될 것이다.
----------------------------------------------
mysql> create table pcs (
-> pid INT, // product id
-> spec char(3),
-> os char(10),
-> ram INT,
-> hd char(4)
-> );
-----------------------------------------------
두번째 테이블은 제조업자의 다양한 고객들에 관한 데이터로 이루어질 것이다.
-----------------------------------------------
mysql> create table clients (
-> name char(25),
-> cid char(8), // client id
-> email char(25),
-> tel char(10)
-> );
-----------------------------------------------
세번째 테이블은 주문 정보에 관한 데이타를 포함할 것이다.
-----------------------------------------------
mysql> create table orders (
-> order_date date,
-> pid INT,
-> cid char(8)
-> );
-----------------------------------------------
◆◆ 자료(Data) 삽입하기
각각의 테이블에 아래와 같이 자료를 삽입해 보자.
☆ pcs (테이블1)
+------+------+-------+------+------+
| pid | spec | os | ram | hd |
+------+------+-------+------+------+
| 1 | 386 | Linux | 64 | 3.1 |
| 2 | 386 | Linux | 128 | 4.2 |
| 3 | 486 | WinNT | 64 | 3.1 |
| 4 | 586 | Linux | 128 | 4.2 |
| 5 | 586 | Win98 | 128 | 6.4 |
+------+------+-------+------+------+
[삽입방법]
-----------------------------------------------------------
mysql> INSERT INTO pcs (pid, spec, os, ram, hd)
-> VALUES (1, '386', 'Linux', 64, '3.1');
-----------------------------------------------------------
☆ clients (테이블2)
+--------+---------+---------------------------+------------+
| name | cid | email | tel |
+--------+---------+---------------------------+------------+
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 |
| 홍길동 | hgd-043 | honggd at won.hongik.ac.kr | 421-555-34 |
| 이쁘니 | pty-042 | pretty at won.hongik.ac.kr | 459-555-32 |
| 못난이 | ugy-043 | ugly at won.hongik.ac.kr | 439-555-88 |
+--------+---------+---------------------------+------------+
[삽입방법]
-----------------------------------------------------------
mysql> INSERT INTO clients (name, cid, email, tel)
-> VALUES ('원주희', 'wjh-042',
-> 'haremoon at won.hongik.ac.kr', '123-456-7890');
-----------------------------------------------------------
☆ orders (테이블3)
+------------+------+---------+
| order_date | pid | cid |
+------------+------+---------+
| 1999-12-05 | 2 | wjh-042 |
| 1999-12-04 | 3 | hgd-043 |
| 1999-12-04 | 1 | wjh-042 |
| 1999-12-05 | 2 | wjh-042 |
| 1999-12-12 | 5 | ugy-043 |
| 1999-12-05 | 5 | pty-042 |
+------------+------+---------+
[삽입방법]
-----------------------------------------------------------
mysql> INSERT INTO orders (order_date, pid, cid)
-> VALUES ('1999-12-05', 2, 'wjh-042');
-----------------------------------------------------------
자, 이제부터 만들어진 3개의 테이블로부터 필요한 데이터만을 추출해 결합하는
방법에 대해 알아보자. 만일 당신의 상사가 특정한 날에 특정한 PC를 주문한 모든
고객의 이메일 목록을 원한다고 하자! 또는 특정한 고객에 의해 작성된 주문서에
있는 RAM의 양을 보고받기를 원한다고 하자. 이러한 모든 일들은 다양한 join문에
의해 쉽게 수행될 수 있다. 만들어진 테이블을 사용해 첫번째 join문을 생성해보고
작성해보자.
◆◆ The Cross Join
Cross Join은 가장 기본적인 join의 타입으로 한 테이블에 있는 각각의 열이 다른
테이블의 모든 열에 간단하게 매치되어 출력된다. 능률적이지는 않지만, 모든 join
의 공통된 특징을 나타내준다.
Cross Join의 간단한 예 :
----------------------------------------------
mysql> SELECT * FROM pcs, clients;
----------------------------------------------
매우 많은 열들이 출력될 것이다. 테이블1(pcs)에 있는 각각의 열이
테이블2(clients)
의 모든 열에 매치된다는 것을 기억하자. 따라서, 3 열을 가진 테이블1(pcs)과 4
열을
가진 테이블2(clients)를 포함한 join문은 총 12 열의 테이블을 만들것이다.
즉 cross-join은 테이블1에 있는 각각의 열들이 테이블2에 있는 모든열들을 한 번씩
교차해 출력한다고 기억하는 것이 쉬울 것같다.
첫번째 join을 성공적으로 수행했다면 다음의 예도 어렵지 않을 것이다.
아래의 예를 따라해 보고 어떤 결과가 출력될지 예상해보자.
-----------------------------------------------------------------------------
mysql> select c.name, o.cid from orders o, clients c where o.cid = "wjh-042";
-----------------------------------------------------------------------------
+--------+---------+
| name | cid |
+--------+---------+
| 원주희 | wjh-042 |
| 원주희 | wjh-042 |
| 원주희 | wjh-042 |
| 홍길동 | wjh-042 |
| 홍길동 | wjh-042 |
| 홍길동 | wjh-042 |
| 이쁘니 | wjh-042 |
| 이쁘니 | wjh-042 |
| 이쁘니 | wjh-042 |
| 못난이 | wjh-042 |
| 못난이 | wjh-042 |
| 못난이 | wjh-042 |
+--------+---------+
예상한 대로 결과가 출력되었나? clients 테이블에 있는 각각의 name이 orders테이
블의 "wjh-042"를 포함한 열마다 매치되어 출력되었다. 지금까지의 설명이 Cross
Join을 설명하는데 충분하지 않으므로 다른 질의를 사용해가며 JOIN을 활용해보기
바란다.
NOTE : 왜 테이블의 이름에 별명을 주어 사용할까? Aliases(별명)은 질의를 입력할
때 반복적인 키의 입력을 줄여주는 방법으로 사용되어진다. 따라서 열을 지정해 줄
때 반복적으로 'clients'를 한자 한자 입력하는 대신에, 질의내에 'from clients c'
를 지정해주고 'c'를 사용할 수 있다.
Cross Join이 테이블들을 연결해 주기는 하지만, 능률적이지는 못하다. 따라서
각각의 테이블들로 부터 우리가 원하는 데이타를 어떻게 하면 쉽게 선택할 수 있는지
계속 다음 장을 읽어보기 바란다.
◆◆ The Equi-join
Equi-join은 한 테이블에 있는 어떠한 값이 두번째(또는 다수의) 테이블내에 포함된
값에 일치 할 때 수행된다.
product id 가 1인 PC를 주문한 고객의 목록을 원한다고 가정해 보자.
-------------------------------------------------------------------
mysql> select p.os, c.name from orders o, pcs p, clients c
-> where p.pid=o.pid and o.pid = 1 and o.cid=c.cid;
-------------------------------------------------------------------
+-------+--------+
| os | name |
+-------+--------+
| Linux | 원주희 |
+-------+--------+
◆ Non-Equi-join
Equi-join은 다수의 테이블들 사이에서 일치하는 자료들만을 추출해낸다. 그러나
만일 일치하지 않은 자료들만을 추출해야 한다면...? 예를 들어, 당신의 상사가
주문한 pid가 제품의 pid보다 더 큰 order id의 모든 운영체제(OS)의 목록을
필요로 한다면 어떻게 할 것인가? 적당히 이름을 non-equi join라고 하겠다.
-------------------------------------------------------------------
mysql> SELECT p.os, o.pid from orders o, pcs p where o.pid > p.pid;
-------------------------------------------------------------------
+-------+------+
| os | pid |
+-------+------+
| Linux | 2 |
| Linux | 3 |
| Linux | 2 |
| Linux | 5 |
| Linux | 5 |
| Linux | 3 |
| Linux | 5 |
| Linux | 5 |
| WinNT | 5 |
| WinNT | 5 |
| Linux | 5 |
| Linux | 5 |
+-------+------+
orders 테이블의 pid가 pcs테이블의 pid보다 더 큰 모든 열들이 매치될 것이다.
주의깊게 살펴보면, 여러가지 제한을 준 간단한 cross-join 임을 파악할 수 있
을 것이다. 상사에게는 특별하게 유용하지 않을 지도 모르지만, 매우 유용한 기
능인 left join을 위한 준비 과정으로 생각하자. 자, 이제 다음장으로 가서
left join을 사용할 때 유용할 수있는 옵션들에 대해 집중적으로 알아보자.
◆◆ The Left Join
Left Join은 사용자가 어떠한 제한을 기반으로 관심있는 모든 종류의 자료를 추출
하게한다. 테이블 join중 가장 막강한 옵션으로, 테이블을 매우 쉽게 조작할 수
있게 한다.
만일 상사가 좀더 자세히, 자세히, 자세하게, 자세하게!를 외친다고 가정해보자.
left join이 우리의 문제를 해결해 줄 것이다.
-------------------------------------------------------------------
mysql> select * from orders left join pcs on orders.pid = pcs.pid;
-------------------------------------------------------------------
+------------+------+---------+------+------+-------+------+------+
| order_date | pid | cid | pid | spec | os | ram | hd |
+------------+------+---------+------+------+-------+------+------+
| 1999-12-05 | 2 | wjh-042 | 2 | 386 | Linux | 128 | 4.2 |
| 1999-12-04 | 3 | hgd-043 | 3 | 486 | WinNT | 64 | 3.1 |
| 1999-12-04 | 1 | wjh-042 | 1 | 386 | Linux | 64 | 3.1 |
| 1999-12-05 | 2 | wjh-042 | 2 | 386 | Linux | 128 | 4.2 |
| 1999-12-12 | 5 | ugy-043 | 5 | 586 | Win98 | 128 | 6.4 |
| 1999-12-05 | 5 | pty-042 | 5 | 586 | Win98 | 128 | 6.4 |
+------------+------+---------+------+------+-------+------+------+
고객이 주문한 모든 PC들의 목록을 추출해 낸다. 예를 들어, PHP3 또는 Perl
스크립트를 사용해 영수증을 출력하는데 사용할 수도 있다. 고객들에게 우리회
사로부터 구입한 모든 제품의 목록을 가끔씩 메일로 보내야 할 때에도
clients 테이블과 연결해 사용할 수 있을 것이다.
아래의 예에서 우리는 제품의 id(pid)가 3인 PC의 정보만을 볼 수 있다.
-------------------------------------------------------------------
mysql> select * from orders left join pcs on pcs.pid=3 and pcs.pid=orders.pid;
-------------------------------------------------------------------
+------------+------+---------+------+------+-------+------+------+
| order_date | pid | cid | pid | spec | os | ram | hd |
+------------+------+---------+------+------+-------+------+------+
| 1999-12-05 | 2 | wjh-042 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-04 | 3 | hgd-043 | 3 | 486 | WinNT | 64 | 3.1 |
| 1999-12-04 | 1 | wjh-042 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-05 | 2 | wjh-042 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-12 | 5 | ugy-043 | NULL | NULL | NULL | NULL | NULL |
| 1999-12-05 | 5 | pty-042 | NULL | NULL | NULL | NULL | NULL |
+------------+------+---------+------+------+-------+------+------+
◆ The Using Clause
left join에 약간의 옵션을 주어 둘 이상의 테이블에 있는 동일한 컬럼을 조금 더
깊게 연관지을수도 있다. on과 using옵션이 사용되며, 아래의 예제를 참조하자.
--------------------------------------------------------------------
## 원본의 예제는 아래와 같지만, 에러가 발생해 필자가 MySQL매뉴얼을 참조해
나름대로 수정을 했다.##
mysql> SELECT * from clients join on orders where clients.cid = orders.cid;
mysql> SELECT * from clients join on orders using (cid);
-------------------------------------------------------------------
==> 수정한 예제
-------------------------------------------------------------------
mysql> SELECT * from clients left join orders on clients.cid = orders.cid;
-------------------------------------------------------------------
또는 아래와 같이 나타낼 수도 있다.
-------------------------------------------------------------------
mysql> SELECT * from clients left join orders using (cid);
-------------------------------------------------------------------
두 예제 모두 똑같은 결과가 출력될 것이다.
+--------+---------+---------------------------+------------+------------+------+---------+
| name | cid | email | tel | order_date | pid |
cid |
+--------+---------+---------------------------+------------+------------+------+---------+
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 | 1999-12-05 | 2 |
wjh-042 |
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 | 1999-12-04 | 1
| wjh-042 |
| 원주희 | wjh-042 | haremoon at won.hongik.ac.kr | 123-456-78 | 1999-12-05 | 2
| wjh-042 |
| 홍길동 | hgd-043 | honggd at won.hongik.ac.kr | 421-555-34 | 1999-12-04 | 3
| hgd-043 |
| 이쁘니 | pty-042 | pretty at won.hongik.ac.kr | 459-555-32 | 1999-12-05 | 5
| pty-042 |
| 못난이 | ugy-043 | ugly at won.hongik.ac.kr | 439-555-88 | 1999-12-12 | 5
| ugy-043 |
+--------+---------+---------------------------+------------+------------+------+---------+
다른 구문의 예를 적용해 가며 left join에 대해 이해하기 바란다. 공부를 하다보면
left join이 여러분의 개발활동에 매우 중요한 역할을 한 다는 것을 느낄 것이다.
테이블 join에 관한 정보를 좀더 깊게 교환하고 싶다면 http://www.mysql.com에 있는
다양한 토론 그룹을 체크해 보기 바란다.
◆◆ Self-joins
Self-join은 관리자가 하나의 테이블에 관련된 데이타를 집중시키는 막강한 방법을
제공해 준다. 사실, self-join은 그 자신의 테이블에 결합하는 것에 의해 수행된다.
개념의 이해를 위해 예를 들어 설명하겠다.
컴퓨터 워크스테이션을 만드는데 사용되는 하드웨어의 다양한 부품에 관한 정보를
가진 매우 큰 데이타베이스를 관리해야 한다고 가정하자. 워크스테이션은 데스크,
PC, 모니터, 키보드, 마우스등으로 이루어져 있다. 게다가, 데스크는 워크스테이션의
모두 다른 부분의 '부모'라고 생각될 수 있다. 우리는 각 워크스테이션의 레코드가
정확한 자료로 유지되기를 원할 것이며, 유일한 ID번호를 부여함으로써 워크스테이션
의 모든 부분을 구체적으로 관련시킬 것이다. 사실, 각 부분은 항목을 분명하게
해주는
유일한 ID번호와 그것의 부모(데스크) ID번호를 확인하기 위한, 두개의 ID 번호를
포함 것이다.
테이블이 아래와 같다고 가정하자.
mysql> select * from ws;
+---------+-----------+-----------+
| uniq_id | name | parent_id |
+---------+-----------+-----------+
| d001 | desktop | NULL |
| m4gg | monitor | d001 |
| k235 | keyboar | d001 |
| pc345 | 200mhz pc | d001 |
| d002 | desktop | NULL |
| m156 | monitor | d002 |
| k9334 | keyboar | d002 |
| pa556 | 350mhz pc | d002 |
+---------+-----------+-----------+
desktop은 그와 관련된 모든 부분들의 부모와 같으므로 parent_id를 가지고 있지
않음을 주목하자. 지금부터 유용한 정보를 위한 질의를 시작할 것이다. self-join
의 사용법을 쉽게 설명하기 위해 테이블을 간단하게 만들었다.
-------------------------------------------------------------------
mysql> select t1.*, t2.* from ws as t1, ws as t2;
-------------------------------------------------------------------
어떻게 출력되는가? 이전처럼, 첫번째 테이블의 각 열들이 두번째 테이블에 있는
모든 열들에 매치되어 연결되 출력될 것이다. 우리에게 매우 유용하지는 않지만
다시 한번 시도해보고 확인해 보기바란다. 좀더 재미있는 예를 들어보겠다.
-------------------------------------------------------------------
mysql> select parent.uniq_id, parent.name, child.uniq_id, child.name
-> from ws as parent, ws as child
-> where child.parent_id = parent.uniq_id and parent.uniq_id = "d001";
-------------------------------------------------------------------
흥미로운 결과가 출력될 것이다.
+---------+---------+---------+-----------+
| uniq_id | name | uniq_id | name |
+---------+---------+---------+-----------+
| d001 | desktop | m4gg | monitor |
| d001 | desktop | k235 | keyboar |
| d001 | desktop | pc345 | 200mhz pc |
+---------+---------+---------+-----------+
self-join은 테이블의 자료를 검증하는 방법으로도 사용된다. 테이블내에 있는
uniq_id컬럼은 테이블에서 유일해야 하며, 만일 데이타의 엔트리가 깊어 뜻하지
않게 같은 uniq_id를 가진 두개의 항목이 데이타베이스에 입력된다면 좋지 않은
결과가 생길것이다. 이럴 경우 정기적으로 self-join을 사용해 체크할 수 있다.
우리는 350mhz pc의 uniq_id가 'm156'(이 값은 워크스테이션 'd002'에 속한
모니터의 uniq_id 값이다.)이 되도록 변경했다고 가정하자.
테이블의 내용은 다음과 같이 변경한다.
-------------------------------------------------------------------
mysql> update ws set uniq_id = 'm156' where name = '350mhz pc';
-------------------------------------------------------------------
아래의 예를 참고해 ws테이블에 self-join을 적용해보자.
-------------------------------------------------------------------
mysql> select parent.uniq_id, parent.name, child.uniq_id, child.name
-> from ws as parent, ws as child
-> where parent.uniq_id = child.uniq_id and parent.name <> child.name;
-------------------------------------------------------------------
아래와 같이 출력될 것이다.
+---------+-----------+---------+-----------+
| uniq_id | name | uniq_id | name |
+---------+-----------+---------+-----------+
| m156 | 350mhz pc | m156 | monitor |
| m156 | monitor | m156 | 350mhz pc |
+---------+-----------+---------+-----------+
Table join은 데이터베이의 관리를 쉽게 도와줄것이다. 구문의 이해를 정확하게
하기위해서 예제에서 배운 명령을 다양하게 변화시켜 적용해보기 바란다.
---- MySQL_Tables_Joins.txt 내용 --------------------------
-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-*-
원본사이트: http://www.devshed.com/Server_Side/MySQL/Join/
* MySQL Table Joins
*(o) By W.J. Gilmore
*(o)| July 06, 1999
(o)| | 번역 : 원주희(lolol@shinan.hongik.ac.kr)
=======================================================================
[영어실력이 너무 부족하다보니 잘못된 부분이 있을 수도 있습니다.
고쳐야할 부분이 있으면 꼭 메일을 보내주세요.]
◆◆ 소개하기
SQL(Structured Query Language)의 가장 큰 특징 중의 하나는 여러개의 테이블을
연결시켜 데이터를 검색하거나 조작할 수 있는 기능이다. 이것은 데이터를 쉽고
빠르게 검색하고 불필요한 데이터를 줄여주는 장점이 있다. 다른 SQL 언어와 마찬
가지로 MySQL도 join명령어로 이 연산을 수행한다.
간단히 말하면 join은 두개 이상의 테이블로부터 필요한 데이터를 연결해 하나의
포괄적인 구조로 결합시키는 연산이다.
예를 들어, 한 컴퓨터 제조업자가 자신의 데이터를 능률적으로 관리하기 위한
데이터베이스가 필요하다고 하자. 이 데이터들은
......생략
원본 : http://database.sarang.net/?inc=read&aid=24199&criteria=mysql&subcrit=&id=&limit=20&keyword=explain&page=1
# 이글은 mysql document 의 7.2.1 Explain Syntax 를 대~충 번역한 것입니다.
# 틈틈이 번역하고 있으나 언제 완료될지 모릅니다..
EXPLAIN 을 사용함으로써 인덱스가 적절히 사용되고 있는지 검토할 수 있다. 인덱스가 잘못 사용되고 있다면 ANALYZE TABLE 을 사용하여 테이블을 점검하라.
이것은 테이블의 상태를 갱신하며 옵티마이저의 동작에 영향을 준다.
옵티마이저가 SELECT 에 기록된 순서대로 조인을 행하게 강제하려면 SELECT 대신에 SELECT STRAIGHT_JOIN 을 사용하라.
EXPLAIN 은 SELECT 문에 사용된 각 테이블당 하나의 행을 리턴한다. 나열된 순서는 MYSQL 이 쿼리처리에 사용하는 순서대로 출력된다.
MYSQL 은 모든 조인을 single-sweep multi-join 방식을 사용하여 해결한다. 이것은 MYSQL 이 첫번째 테이블에서 한행을 읽고, 두번째 테이블에서 매치되는 행을 찾고, 세번째 테이블에서 매치되는 행을 찾고.. 그러한 방식이다. 모든 테이블들이 처리된 후 추출된 컬럼을 출력하고 다시 처음 테이블로 돌아가서 조인을 계속한다. 이런식으로 첫번째 테이블에 더이상 남는행이 없을때까지 실행한다.
(어느것이 첫번째 테이블이 될지는 mysql 옵티마이저가 결정할 문제이다. STRAIGHT_JOIN 을 명시하지 않았다면 유저가 입력한 순서와는 관련이 없다.)
MYSQL 4.1 버전에서 EXPLAIN 의 출력포멧이 UNION 과 subquery, derived table 을 다루기에 더 효과적으로 변경되었다. 무엇보다 중요한 것은 id , select_type 의 두 컬럼이 추가된 것이다.
EXPLAIN 의 각 행은 하나의 테이블에 대한 정보를 보여주며 다음과 같은 컬럼들로 구성된다.
idSELECT 번호, 쿼리내의 SELECT 의 구분번호이다.
select_typeSELECT 의 타입, 다음과 같다.
SIMPLE단순 SELECT (UNION 이나 서브쿼리를 사용하지 않음)
PRIMARY가장 외곽의 SELECT
UNIONUNION 에서의 두번째 혹은 나중에 따라오는 SELECT
DEPENDENT UNIONUNION 에서의 두번째 혹은 나중에 따라오는 SELECT, 외곽쿼리에 의존적이다.
UNION RESULTUNION 의 결과물.
SUBQUERY서브쿼리의 첫번째 SELECT
DEPENDENT SUBQUERY서브쿼리의 첫번째 SELECT, 외곽쿼리에 의존적이다.
DERIVEDSELECT 로 추출된 테이블 (FROM 절 내부의 서브쿼리)
table나타난 결과가 참조하는 테이블명.
type조인타입, 아래와 같다. 우수한 순서대로 뒤로갈수록 나쁜 조인형태이다.
system테이블에 단 하나의 행만 존재(시스템 테이블). const join 의 특수한 경우이다.
const많아야 하나의 매치되는 행만 존재하는 경우. 하나의 행이기 때문에 각 컬럼값은 나머지 연산에서 상수로 간주되며, 처음 한번만 읽어들이면 되기 때문에 무지 빠르다.
PRIMARY KEY 나UNIQUEindex 를 상수와 비교하는 경우.
아래의 경우에서 tbl_name 은 const table 로 조인된다.
SELECT * FROMtbl_nameWHEREprimary_key=1;
SELECT * FROMtbl_name
WHEREprimary_key_part1=1 ANDprimary_key_part2=2;
eq_ref조인수행을 위해 각 테이블에서 하나씩의 행만이 읽혀지는 형태. const 타입이외에 가장 훌륭한 조인타입니다.
조인연산에 PRIMARY KEY 나UNIQUEindex 인덱스가 사용되는 경우.
인덱스된 컬럼이 = 연산에 사용되는 경우. 비교되는 값은 상수이거나 이전조인결과의 컬럼값일수 있다.
다음 예에서 MySQL 은 ref_table 을 처리하는데 eq_ref 조인을 사용한다.
SELECT * FROMref_table,other_table
WHEREref_table.key_column=other_table.column;
SELECT * FROMref_table,other_table
WHEREref_table.key_column_part1=other_table.column
ANDref_table.key_column_part2=1;
ref이전 테이블과의 조인에 사용될 매치되는 인덱스의 모든행이 이 테이블에서 읽혀진다. leftmost prefix 키만을 사용하거나 사용된 키가 PRIMARY KEY 나
UNIQUE가 아닐때(즉 키값으로 단일행을 추출할수 없을때) 사용되는 조인.
만약 사용된 키가 적은수의 행과 매치될때 이것은 적절한 조인 타입니다.
ref 는 인덱스된 컬럼과 = 연산에서 사용된다.
아래 예에서 MySQL 은 ref_table 처리에 ref 조인 타입을 사용한다.
SELECT * FROMref_tableWHEREkey_column=expr;
SELECT * FROMref_table,other_table
WHEREref_table.key_column=other_table.column;
SELECT * FROMref_table,other_table
WHEREref_table.key_column_part1=other_table.column
ANDref_table.key_column_part2=1;
ref_or_nullref 와 같지만 NULL 값을 포함하는 행에대한 검색이 수반된다.
4.1.1 에서 새롭게 도입된 조인타입이며 서브쿼리 처리에서 대개 사용된다.
아래 예에서 MySQL 은 ref_table 처리에 ref_or_null 조인타입을 사용한다.SELECT * FROM
ref_tableWHEREkey_column=exprORkey_columnIS NULL;index_merge인덱스 병합 최적화가 적용되는 조인 타입.
이 경우, key 컬럼은 사용된 인덱스의 리스트를 나타내며 key_len 컬럼은 사용된 인덱스중 가장 긴 key 명을 나타낸다.
For more information, see Section 7.2.6, “Index Merge Optimization”.
unique_subquery이것은 아래와 같은 몇몇 IN 서브쿼리 처리에서 ref 타입대신 사용된다.
valueprimary_keyFROMsingle_tableWHEREsome_expr)
unique_subquery 는 성능향상을 위해 서브쿼리를 단순 index 검색 함수로 대체한다.
index_subqueryunique_subquery 와 마찬가지로 IN 서브쿼리를 대체한다. 그러나 이것은 아래와 같이 서브쿼리에서 non-unique 인덱스가 사용될때 동작한다.
valuekey_columnFROMsingle_tableWHEREsome_expr)
range인덱스를 사용하여 주어진 범위 내의 행들만 추출된다. key 컬럼은 사용된 인덱스를 나타내고 key_len 는 사용된 가장 긴 key 부분을 나타낸다.
ref 컬럼은 이 타입의 조인에서 NULL 이다.
range 타입은 키 컬럼이 상수와=,<>,>,>=,<,<=,IS NULL,<=>,BETWEEN 또는IN연산에 사용될때 적용된다.
SELECT * FROM
tbl_nameWHEREkey_column= 10; SELECT * FROMtbl_nameWHEREkey_columnBETWEEN 10 and 20; SELECT * FROMtbl_nameWHEREkey_columnIN (10,20,30); SELECT * FROMtbl_nameWHEREkey_part1= 10 ANDkey_part2IN (10,20,30);
index이 타입은 인덱스가 스캔된다는걸 제외하면 ALL 과 같다. 일반적으로 인덱스 파일이 데이타파일보다 작기 때문에 ALL 보다는 빠르다.
MySQL 은 쿼리에서 단일 인덱스의 일부분인 컬럼을 사용할때 이 조인타입을 적용한다.
ALL이전 테이블과의 조인을 위해 풀스캔이 된다. 만약 (조인에 쓰인) 첫번째 테이블이 고정이 아니라면 비효율적이다, 그리고 대부분의 경우에 아주 느린 성능을 보인다. 보통 상수값이나 상수인 컬럼값으로 row를 추출하도록 인덱스를 추가함으로써 ALL 타입을 피할 수 있다.
possible_keys이 컬럼값은 MySQL 이 해당 테이블의 검색에 사용할수 있는 인덱스들을 나타낸다.
주의할것은 explain 결과에서 나타난 테이블들의 순서와는 무관하다는 것이다.
이것은 possible_keys 에 나타난 인덱스들이 결과에 나타난 테이블 순서에서 실제 사용할 수 없을수도 있다는 것을 의미한다.
이값이 NULL 이라면 사용가능한 인덱스가 없다는 것이다. 이러한 경우에는 인덱스를 where 절을 고려하여 사용됨직한 적절한 컬럼에 인덱스를 추가함으로써 성능을 개선할 수 있다. 인덱스를 수정하였다면 다시한번 EXPLAIN 을 실행하여 체크하라.
See Section 13.2.2, “ALTER TABLESyntax”.현재 테이블의 인덱스를 보기 위해서는
SHOW INDEX FROM.을 사용하라.tbl_namekey이 컬럼은 MySQL 이 실제 사용한 key(index) 를 나타낸다.
만약 사용한 인덱스가 없다면 NULL 값일 것이다. MySQL 이 possible_keys 에 나타난 인덱스를 사용하거나 사용하지 않도록 강제하려면 FORCE INDEX,USE INDEX, 혹은IGNORE INDEX를 함께 사용하라.
See Section 13.1.7, “SELECTSyntax”.MyISAM 과
BDB테이블에서는 ANALYZE TABLE 이 옵티마이저가 더나은 인덱스를 선택할 수 있도록 테이블의 정보를 갱신한다.
MyISAM 에서는 myisamchk --analyze 가 같은 기능을 한다.
See Section 13.5.2.1, “ANALYZE TABLESyntax” and Section 5.7.2, “Table Maintenance and Crash Recovery”.key_len이 컬럼은 MySQL 이 사용한 인덱스의 길이를 나타낸다. key 컬럼값이 NULL 이면 이값도 NULL 이다.
key_len 값으로 MySQL 이 실제 복수컬럼 키중 얼마나 많은 부분을 사용할 것인지 알 수 있다.
ref이 컬럼은 행을 추출하는데 키와 함께 사용된 컬럼이나 상수값을 나타낸다.
rows이 값은 쿼리 수행에서 MySQL 이 예상하는 검색해야할 행수를 나타낸다.
Extra이 컬럼은 MySQL 이 쿼리를 해석한 추가적인 정보를 나타낸다.
아래와 같은 값들이 나타날 수 있다.
DistinctMySQL 이 매치되는 첫행을 찾는 즉시 검색을 중단할 것이다.
Not existsMySQL 이 LEFT JOIN 을 수행함에 매치되는 한 행을 찾으면 더이상 매치되는 행을 검색하지 않는다.
아래와 같은 경우에 해당한다.SELECT * FROM t1 LEFT JOIN t2 ON t1.id=t2.id WHERE t2.id IS NULL;
여기서 t2.id 는 NOT NULL 이고, 이경우 MySQL 은 t1 을 스캔한 후 t1.id 값을 사용해 t2 를 검색한다. MySQL 이 t2 에서 매치되는 행을 찾으면 t2.id 는 NULL 이 될 수 없으므로 더이상 진행하지 않는다. 즉, t1 의 각 행에 대해 t2 에서 매치되는 행이 몇개가 있던지 한개만 찾으면 된다.
range checked for each record (index map: #)MySQL 이 사용할 좋은 인덱스가 없다. 그러나 선행된 테이블의 컬럼값에 따라 몇몇 인덱스를 사용할 수 있다. 선행된 테이블의 개개 행에 대해 MySQL 이 range 나 index_merge 접근법을 사용할 수 있는지 체크할 것이다.
적용가능성의 핵심은 Section 7.2.5, “Range Optimization” and Section 7.2.6, “Index Merge Optimization” 에 모든 선행된 테이블의 값이 명확하거나 상수인 때를 예외로 하여 기술되어 있다.
이것은 그리 빠르진 않으나 인덱스가 없는 조인의 경우보다는 빠르다.Using filesortMySQL 이 정렬을 위해 추가적인 과정을 필요로한다. 정렬과정은 조인타입에 따라 모든 행을 검색하고 WHERE 절에 의해 매치된 모든 행들의 키값을 저장한다. 그리고 저장된 키값을 정렬하여 재정렬된 순서로 행들을 추출한다.
See Section 7.2.10, “How MySQL OptimizesORDER BY”.
Using index컬럼정보가 실제 테이블이 아닌 인덱스트리에서 추출된다. 쿼리에서 단일 인덱스된 컬럼들만을 사용하는 경우이다.
Using temporaryMySQL 이 결과의 재사용을 위해 임시테이블을 사용한다. 쿼리 내에 GROUP BY 와 ORDER BY 절이 각기 다른 컬럼을 사용할때 발생한다.
Using whereWHERE 절이 다음 조인에 사용될 행이나 클라이언트에게 돌려질 행을 제한하는 경우이다. 테이블의 모든 행을 검사할 의도가 아니라면 Extra 값이 Using where 가 아니고 조인타입이 ALL 이나 index 라면 쿼리사용이 잘못되었다.
쿼리를 가능한 한 빠르게 하려면, Extra 값의 Using filesort 나 Using temporary 에 주의해야 한다.
Using sort_union(...) ,Using union(...),Using intersect(...)
이들은 인덱스 병합 조인타입에서 인덱스 스캔이 병합되는 형태를 말한다.
See Section 7.2.6, “Index Merge Optimization” for more information.
Using index for group-by테이블 접근방식은 Using index 와 같다. MySQL 이 실제 테이블에 대한 어떠한 추가적인 디스크 접근 없이 GROUP BY 나 DICTINCT 쿼리에 사용된 모든 컬럼에 대한 인덱스를 찾았음을 말한다. 추가적으로 각각의 group 에 단지 몇개의 인덱스 항목만이 읽혀지도록 가장 효율적인 방식으로 인덱스가 사용될 것이다.
For details, see Section 7.2.11, “How MySQL OptimizesGROUP BY”.
EXPLAIN 의 출력내용중 rows 컬럼값들을 곱해봄으로써 얼마나 효과적인 join 을 실행하고 있는지 알 수 있다. 이 값은 MySQL 이 쿼리수행중 검사해야할 행수를 대략적으로 알려준다. 만약 max_join_size 시스템 변수값을 설정하였다면 이 값은 또한 여러테이블을 사용하는 select 중 어느것을 먼저 실행할지 판단하는데 사용된다.
See Section 7.5.2, “Tuning Server Parameters”.
다음 예는 다중테이블 조인이 EXPLAIN 정보를 통해 점차적으로 개선되는 과정을 보여준다. 만약 아래와 같은 select 문을 EXPLAIN 으로 개선한다면 :
EXPLAIN SELECT tt.TicketNumber, tt.TimeIn,
tt.ProjectReference, tt.EstimatedShipDate,
tt.ActualShipDate, tt.ClientID,
tt.ServiceCodes, tt.RepetitiveID,
tt.CurrentProcess, tt.CurrentDPPerson,
tt.RecordVolume, tt.DPPrinted, et.COUNTRY,
et_1.COUNTRY, do.CUSTNAME
FROM tt, et, et AS et_1, do
WHERE tt.SubmitTime IS NULL
AND tt.ActualPC = et.EMPLOYID
AND tt.AssignedPC = et_1.EMPLOYID
AND tt.ClientID = do.CUSTNMBR;
이 예에서 아래와 같은 가정이 사용되었다.:
The columns being compared have been declared as follows:
Table Column Column Type ttActualPCCHAR(10)ttAssignedPCCHAR(10)ttClientIDCHAR(10)etEMPLOYIDCHAR(15)doCUSTNMBRCHAR(15)The tables have the following indexes:
Table Index ttActualPCttAssignedPCttClientIDetEMPLOYID(primary key)doCUSTNMBR(primary key)The
tt.ActualPCvalues are not evenly distributed.
먼저, 개선되기 전의 EXPLAIN 은 다음과 같은 정보를 보여준다.:
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
do ALL PRIMARY NULL NULL NULL 2135
et_1 ALL PRIMARY NULL NULL NULL 74
tt ALL AssignedPC, NULL NULL NULL 3872
ClientID,
ActualPC
range checked for each record (key map: 35)
각 테이블의 type 이 ALL 을 나타내므로, MySQL 이 모든 테이블의 카티션곱(Cartesian product) 를 생성한다는 것을 나타낸다.
각 테이블의 행의 조합이 모두 검사되어야 하기 때문에 이것은 아주 오랜 시간이 소요될 것이다.
실제로 이 결과는 74 * 2135 * 74 * 3872 = 45,268,558,720 행에 달한다.
만약 테이블이 더 크다면 얼마나 소요될지 상상할 수도 없을 것이다.
여기서 우선적인 문제는 MySQL 은 같은 타입으로 선언된 컬럼의 인덱스를 더 효과적으로 사용할 수 있다는 것이다. (ISAM 테이블에서는 같은 타입으로 선언되지 않은 인덱스는 사용할 수 없다.) 여기에서 VARCHAR 과 CHAR 은 길이가 다르지 않다면 같은 타입이다.
tt.ActualPC 는 CHAR(10) 이고 et.EMPLOYID 는 CHAR(15) 로 선언되어 있으므로 길이의 불일치가 발생한다.
이러한 컬럼 길이의 불일치 문제의 해결을 위해 ALTER TABLE 을 사용하여 ActualPC 컬럼을 10 글자에서 15 글자로 변경하자 (길이를 늘리는것은 데이타 손실이 없다.)
mysql> ALTER TABLE tt MODIFY ActualPC VARCHAR(15);
이제 tt.ActualPC 와 et.EMPLYID 는 모두 VARCHAR(15) 이다. 다시 EXPLAIN 을 실행해보면 다음 결과와 같다.
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC, NULL NULL NULL 3872 Using
ClientID, where
ActualPC
do ALL PRIMARY NULL NULL NULL 2135
range checked for each record (key map: 1)
et_1 ALL PRIMARY NULL NULL NULL 74
range checked for each record (key map: 1)
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
훨씬 좋아졌지만 아직 완벽하지 않다. 행의 곱은 이제 74 만큼 줄었다.
이 쿼리는 이제 몇초만에 실행될 것이다.
두번째 작업은 tt.AssignedPC = et_1.EMPLYID 와 tt.ClientID = do.CUSTNMBR 에서의 컬럼길이의 불일치를 수정하는 것이다.
mysql> ALTER TABLE tt MODIFY AssignedPC VARCHAR(15),
-> MODIFY ClientID VARCHAR(15);
이제 EXPLAIN 은 다음과 같은 결과를 보여준다.
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
tt ref AssignedPC, ActualPC 15 et.EMPLOYID 52 Using
ClientID, where
ActualPC
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
이것은 이제 거의 최적의 결과가 된 것 같다.
남아있는 문제는 MySQL 이 기본으로 tt.ActualPC 컬럼의 값이 균등하게 분포되어 있다고 가정한다는 것이다. 하지만 tt 테이블은 실제로 그렇지 않다.
다행히도 MySQL 이 키 분포를 검사하도록 하는것은 매우 쉽다.
mysql> ANALYZE TABLE tt;
이제 완벽한 조인이 되었다. EXPLAIN 결과는 다음과 같다.
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC NULL NULL NULL 3872 Using
ClientID, where
ActualPC
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
EXPLAIN 결과의 rows 컬럼값이 나타내는 MySQL 최적화에 의해 예측된 행수에 주목하라.
나타난 숫자가 실제 행수에 근접한지 체크해야 한다. 그렇지 않다면 STRAIGHT_JOIN 를 사용고 FROM 절에서 테이블의 순서를 변경함으로써 더 나은 성능을 얻을 수 있다.